
本記事は全5回のシリーズ記事「Intel Core UltraのNPUで実現するAIモデル」の第2回です。
第1回 CPU附属のNPUを使うには
第2回 OpenVINOを使ったNPU推論
第3回 色々なCNNをNPUで実行する
第4回 OpenVINOモデルの量子化
第5回 Open VINO Gen AIを使ってLLMを実行する
前回まででIntel Core UltraシリーズでNPUを使う方法について調べてきました。 今回からOpenVINOを使用して実際に動かしていきたいと思います。
OpenVINOとは
OpenVINOはIntelが提供するAI推論を最適化するためのツールキットで、Intel製CPU、GPU、NPUなどに対応しています。ONNXやPyTorchで作成したモデルをIntelデバイス用に最適化し、レイテンシやスループットを向上させます。
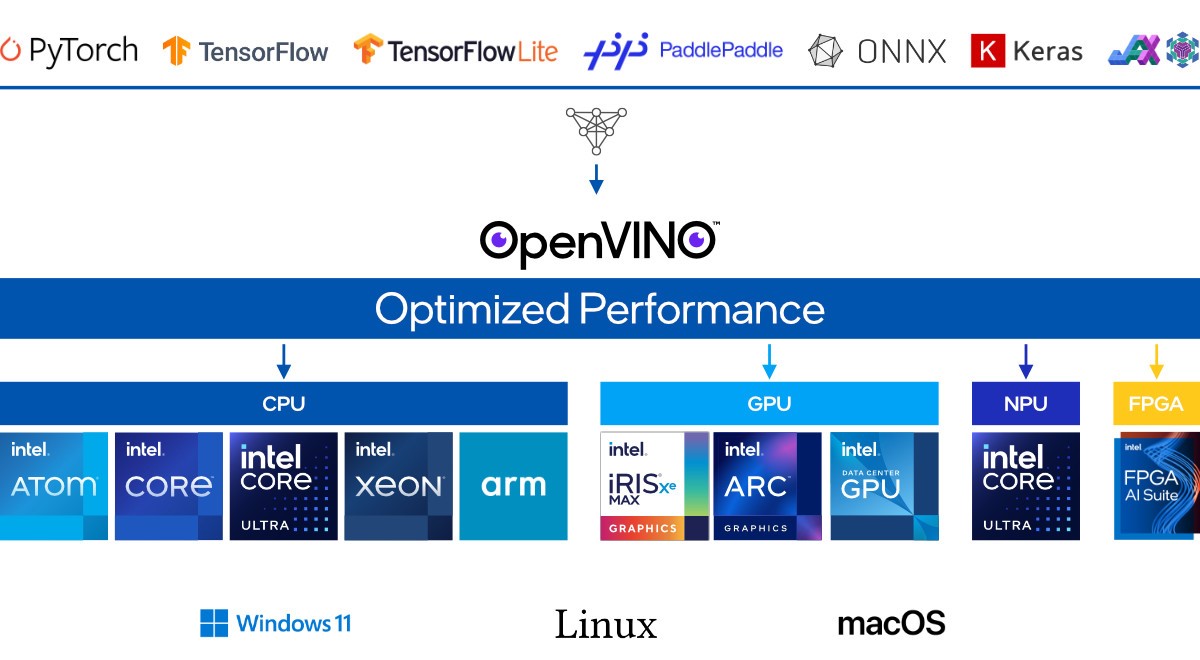
▲ 出典:OpenVINO公式ドキュメント
推論までの流れ
学習済みのAIモデルからOpenVINOを使用した推論までの流れを以下に記します。
- CPytorch, TensorFlow, MxNet, Caffe, Kaldi, ONNXフレームワークでモデルをトレーニング
- ov.Model(IRモデル)形式に変換
- OpenVINOの共通フォーマット
- ov.CompiledModelに変換
- このときにオフロード先のデバイスを選択する
- CompiledModelを使用して推論
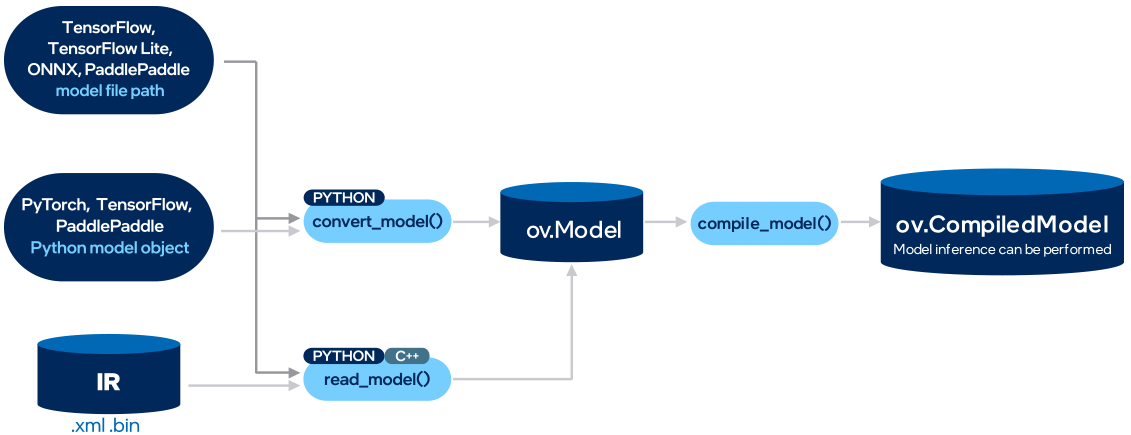
▲ 出典:https://docs.openvino.ai/2024/openvino-workflow.html
主な機能
OpenVinoは色々なツールを提供していますが、NPUでAIモデルを推論する上で役に立ちそうな機能を紹介します。
モデル最適化
量子化や重み圧縮などをすることで、モデル自体のサイズを縮小して、モデルの推論を高速化することができます。量子化アルゴリズムはPTQ(Post Training Quantization)、QAT(Quantization aware Traning)のどちらも提供しています。ただしIntelのNPUはINT8, FP16, FP32に対応しているため量子化をせずにNPUで推論することが出来ます。
マルチデバイス実行
複数のデバイスを同時に使用することでスループットが向上し、複数のデバイスが推論ワークロードを共有するため、パフォーマンスの安定性が向上します。「CPUがbusy状態であったらNPUを扱う」ような優先度を持たせた推論なども出来ます。ただし、この機能を十全に扱うためには、モデル推論を非同期処理で動作させるなど、色々と整備する必要があるそうです。
環境構築
今回は以下の環境で進めます(GPUを積んでいますが、OpenVINOでは使用しません)。
- Linux/Ubuntu24.04
- コンテナのベースイメージ:Ubuntu24.04
- デバイス
- CPU: intel Core Ultra7 265KF
- GPU: GeForce RTX4090
- ライブラリ
- Python 3.11
- onnx 1.14.0
ドライバのインストール
以下のサイトからLinux NPU Driverをインストールします。 私はv1.10.1のArrowLake:Ubuntu24.04用をインストールしました。
https://github.com/intel/linux-npu-driver/releases
インストール後、ls /dev/accel/accel0とsudo dmesgでドライバを認識しているか確認出来ます。
ls /dev/accel/accel0
# /dev/accel/accel0
sudo dmesg |grep intel_vpu
# intel_vpuの状態が分かればOKまた、docker環境でintel npuを動かしたい場合はそのままではNPUドライバを認識出来ません。 コンテナを立てるときに–device=/dev/accel/accel0でmaccel0をマウントし、コンテナ内でドライバをインストールし直す必要があります。 ドライバの再インストールに関してはこのissueを参考にしました。
OpenVinoのインストール
- インストール
pip install openvino- NPUを認識しているかの確認
>>> import openvino as ov
>>> core = ov.Core()
>>> core.available_devices
['CPU', 'NPU']NPUの表示があればOK。
NPUを使った推論
ONNXモデルの準備
今回はresnet18を使ってNPU推論をしていこうと思います。 まずはtimmからresnet18の事前学習済みモデルをインストールして、ONNXとして保存します。
OpenVINOで作成するモデルの入力はPytorchなどと異なり固定にする必要があり、今回、モデルの入力サイズは(1, 3, 224, 224)としました。
import timm
import torch
import onnx
model = timm.create_model('resnet18', pretrained=True)
model.eval()
sample_input = torch.rand(1,3,224,224)
onnx_model_path = "resnet18.onnx"
torch.onnx.export(
model,
sample_input,
onnx_model_path,
verbose=False,
input_names=["input"],
output_names=["output"])IRモデルに変換
IRモデルの作成はONNXモデルのパスを指定するだけなので、非常に簡単です。ONNX以外にもPytorchやTensorFlowなども指定することが出来ます。
import openvino as ov
core = ov.Core()
ir_model = ov.convert_model(onnx_model_path)モデルをコンパイル
IRモデルから推論用のモデルへの変換です。 このときに推論デバイスを指定することが出来ます。 コンパイル時間も今回の場合は1秒もかかりませんでした。
device = "NPU"
compiled_model = core.compile_model(ir_model, device)推論
オフロードデバイスの指定はコンパイルのときに出来ているため、モデルに入力を入れるだけで結果が返ってきます。
dummy_input = np.random.rand(1, 3, 224, 224).astype(np.float32)
result_infer = compiled_model([dummy_input])ベンチマーク
Openvinoの附属のベンチマークツールを使用して、レイテンシやFPSを見ていきます。 まずはIRモデルを保存します。
import os
output_dir = 'ir_resnet18'
ov.serialize(ir_model, os.path.join(output_dir, "resnet18.xml"))その後、ir_resnet18ディレクトリにあるxmlモデルを指定して、CLIでベンチマークツールを起動します。
benchmark_app -m ir_resnet18/resnet18.xml -d NPU -hint latencyレイテンシやスループットを測定できました。
[ INFO ] Execution Devices:NPU
[ INFO ] Count: 39584 iterations
[ INFO ] Duration: 60002.73 ms
[ INFO ] Latency:
[ INFO ] Median: 1.44 ms
[ INFO ] Average: 1.44 ms
[ INFO ] Min: 1.23 ms
[ INFO ] Max: 4.74 ms
[ INFO ] Throughput: 659.70 FPS計測時間(Duration)は60秒間でレイテンシ優先で計測しています。 平均のレイテンシは1.44msでフレームレートは659FPSでした。また計測のジッターについては最初の10回ほどはレイテンシは長くその後に収束していく傾向にありました。