
本記事は全5回のシリーズ記事「Intel Core UltraのNPUで実現するAIモデル」の第4回です。
第1回 CPU附属のNPUを使うには
第2回 OpenVINOを使ったNPU推論
第3回 色々なCNNをNPUで実行する
第4回 OpenVINOモデルの量子化
第5回 Open VINO Gen AIを使ってLLMを実行する
はじめに
NPUやFPGAのようなオフロードデバイスは計算の効率化のためINT8にしか対応していない場合を多く見かけますが、Intel Core UltraのNPUはINT8の他にFP16、FP32のデータ型に対応しています。 そのためIntel Core Ultraでは量子化をせずともNPUデバイスで計算を実行することが可能ですが、量子化を行うことで一般的にモデルの推論速度が速くなります。
以下の表はYOLOの開発元が出してるデータであり、Intel Core Ultra 155HでYOLOv8モデルを推論したとき、Pytorch、OpenVINO(FP32)、OpenVINO(INT8)での推論時間になります。
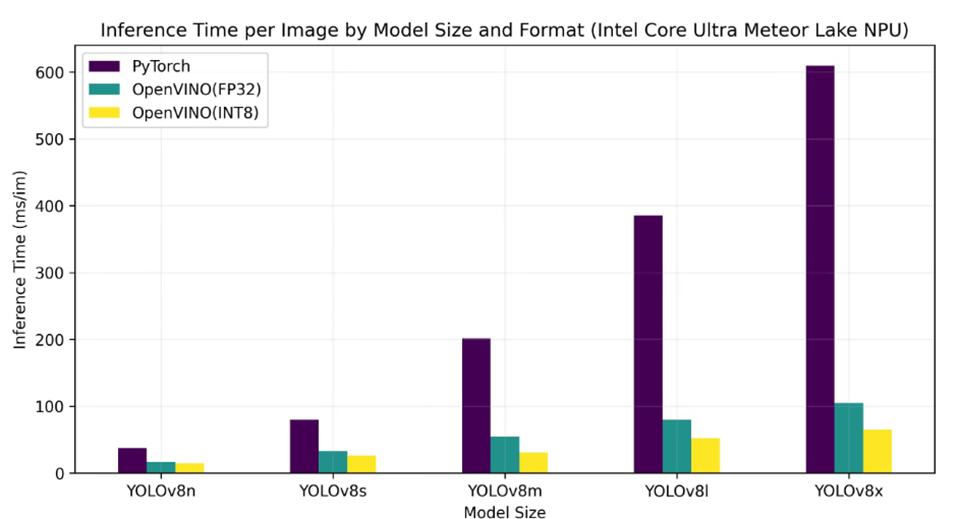
▲ 出典:Ultralytics YOLO 資料
量子化手法
OpenVINOでは量子化を含めたモデルの最適化はNNCFというパッケージを介してできます。NNCFでは以下の最適化の手法を提供しています。
- PTQ
- トレーニング済みモデルの量子化
- QAT
- 量子化を考慮したトレーニング
- Weight Compression
- LLM用の重み圧縮
今回はこのうちのPTQを用いてモデルに8ビット量子化を適用し、推論速度の高速化、量子化誤差を調査していきたいと思います。キャリブレーションデータやテストデータはImageNet、検証するモデルは前回検証に使用したモデルを使っていきたいと思います。
量子化結果
推論速度
以下は量子化前(FP32),量子化後(INT8)のNPU推論速度になります。
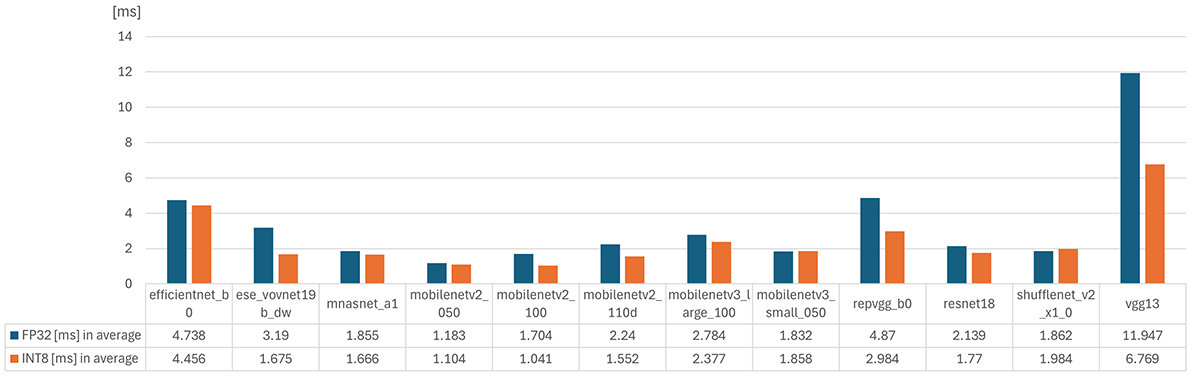
8ビット量子化を実施することで、モデルの推論時間が短縮されることが確認されました。特に、VGG13のような比較的重いモデルにおいて、その効果が顕著に現れました。例えば、VGG13はFP32モードでの推論時間が約12msであったのに対し、INT8に量子化後は6.8msと、レイテンシがほぼ半分に削減されました。このように、8ビット量子化によって推論速度が大きく改善され、特に推論時間が重要なアプリケーションにおいては量子化は有効に働きます。
一方、軽量モデルであるMobileNet系のモデルなどでは、8ビット量子化の効果はあまり顕著ではないように感じました。MobileNetはすでに非常に効率的に設計されており、FP32モードでも比較的短い推論時間を実現しているため、8ビット量子化による推論時間の短縮効果は、VGG13ほど大きくありませんでした。推論時間を意識して開発された軽量モデル(e.g. mobilenet)については、量子化の恩恵を受けづらい傾向にありました。
量子化誤差
以下は量子化前(FP32)と量子化後(INT8)のモデルを用いた推論結果(ラベル)の一致率を量子化誤差指標として算出しました。検証画像はImageNetで事前学習済みモデルを使用して検証しています。量子化前の結果に対する一致率を見ているため、1に近いほど量子化誤差が少なく、0に近いほど量子化誤差が大きいという結果になります。
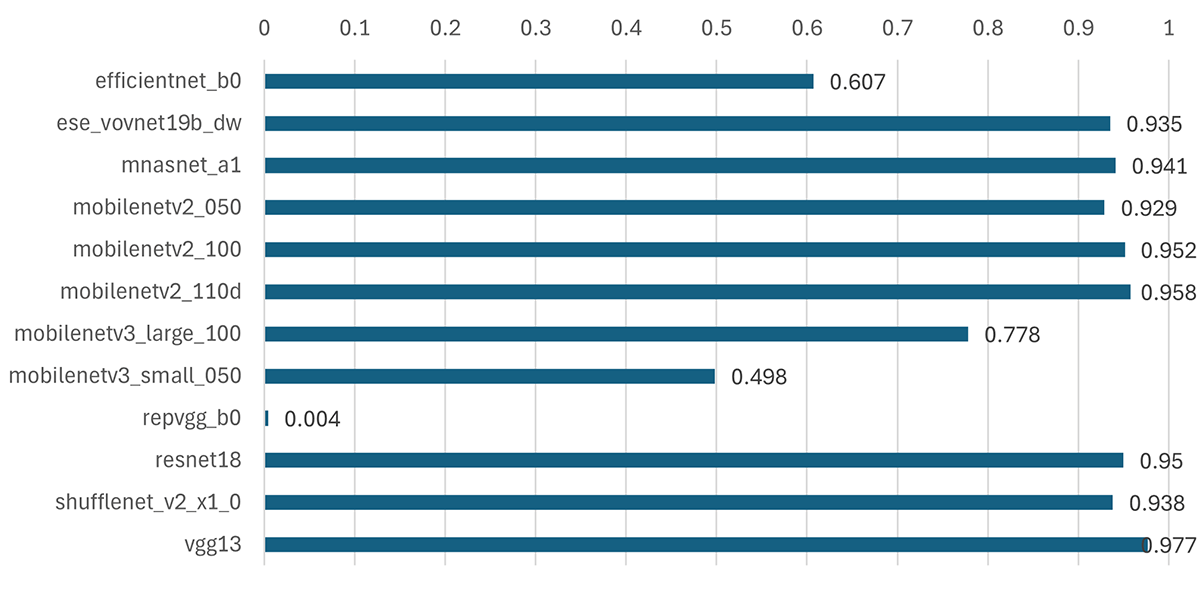
efficientnetやmobilenetv3系、repvggでは量子化誤差の割合が大きくなりましたが、その他では大体95%程の精度となりました。
ONNX Runtimeを使用しての量子化も試してみましたが、量子化誤差としては同様の結果になりました。極端に量子化誤差が大きいモデルがあるのが気になりますが、それほどおかしな結果はではないように思います。
終わりに
量子化を行うことで推論速度は向上しますが、どうしても量子化誤差が出てしまいます。Intel Core Ultraでは、量子化を行わなくても計算可能であるため、システムの要件や精度と速度のバランスを考慮して選択出来るのはよいと思いました。