
本記事は全4回のシリーズ記事「Intel Core UltraのNPUで実現するAIモデル」の第3回です。
第1回 CPU附属のNPUを使うには
第2回 OpenVINOを使ったNPU推論
第3回 色々なCNNをNPUで実行する
第4回 OpenVINOモデルの量子化
はじめに
前回まで、OpenVINOを用いたNPU推論のやり方について見ていきました。 今回は、一歩進んで推論の設定や環境を変更しながら、その結果を比較検討してみます。具体的には、以下の3つの要素を組み合わせながらNPUでの推論結果を分析していきます:
- 推論デバイス NPUに加えて、CPUやGPUなど他のハードウェアでの推論も検討し、各デバイスの性能や特徴を比較します。GPUはNVIDIAのGeForce RTX4090を使用します(内蔵GPUではありません)。
- 推論エンジン OpenVINOに限らず、ONNX RuntimeやPytorchなど異なる推論エンジンを活用して、同じモデルでの推論結果を比較します。
- CNNモデル ResNet、MobileNetなど、異なる深層学習モデルを使用して、画像認識における性能を評価します。モデル構造やモデルサイズによる影響を分析します。
これにより、NPUを用いた推論が他の環境やエンジンとの比較でどのような強みや課題が見えるのかを明らかにします。次節では、具体的な設定と結果比較の手順を解説していきます。
ai_inference_device_benchmark
この記事で実験するベンチマークテストは弊社でOSSとして公開しています。 https://github.com/ispcojp/ai_inference_device_benchmark このリポジトリは色々なデバイスで色々なフレームワーク(現在はPytorch, ONNX Runtime, OpenVINO)でCNNを計測した結果を持ち寄り公平な比較が出来るすることを目的としています。
色々なCNN・デバイス・ライブラリの速度比較
実験環境
- Linux/Ubuntu24.04
- コンテナのベースイメージ:Ubuntu24.04
- デバイス
- CPU: intel Core Ultra7 265KF
- GPU: GeForce RTX4090
- ライブラリ
- Python 3.11
- onnx 1.14.0
- onnxruntime 1.20.1
CNNモデル
実験対象のCNNモデルは以下になります。
- efficientnet_b0
- ese_vovnet19b_dw
- mixnet_s
- mnasnet_a1
- mobilenetv2_050
- mobilenetv2_100
- mobilenetv2_110d
- mobilenetv3_large_100
- mobilenetv3_small_050
- repvgg_b0
- resnet18
- shufflenet_v2_x1_0
- vgg13
推論エンジン
- OpenVINO
- Pytorch
- ONNX Runtime
計測結果
以下の図はモデル毎に使用デバイス、推論エンジンを変更していった際の推論時間(レイテンシ)の結果です。
それぞれのCNNモデルについて、上から順にOpenVINO(NPU)、OpenVINO(CPU)、Pytorch(GPU)、Pytorch(CPU)、ONNX Runtime(CPU)、ONNX Runtime(GPU)を使用したときの推論速度(単位ms)で表したものになります。
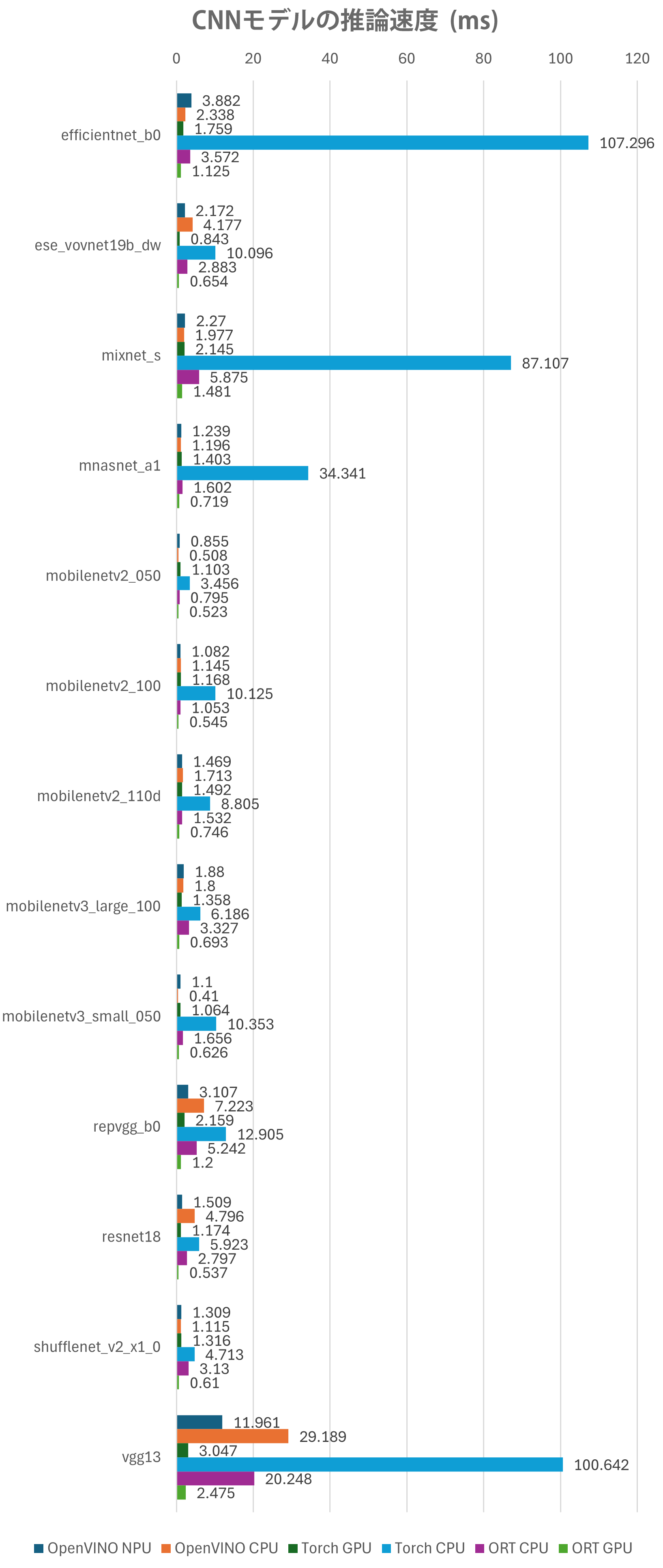
ある程度の傾向は似ているもののモデルによって若干有利不利があり説明しづらいため、Resnet18を例に取り上げてみましょう。
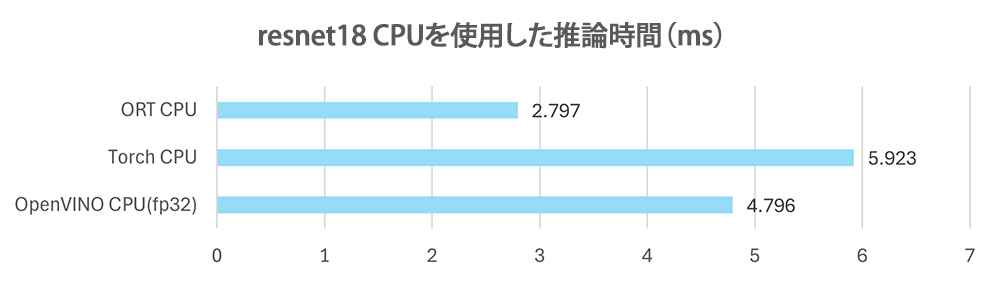
まずはCPUでの推論結果ですが推論速度は、ONNX Runtime < OpenVINO < Pytorh となっています。やはりONNX Runtimeは推論用に最適化がされているため速いです。OpenVINOもIntelのハードウェア向けの最適化をしていると思いますが、今回の評価ではONNX Runtimeが最も速い結果となりました。Pytorchはスクリプトのまま実行しておりTorchScriptなどの推論用の最適化をしていないためか、3つのデバイスの中では一番遅い数値となっています。

Torch GPUやORT GPUの結果を見てみると、GPUが一番速い結果となりました。

またNPUはResnet18においては、CPUとGPUの中間ほどの速度となっていました。
ただモデルによってはCPUがNPUを上回る結果となっているものもありました。これはモデル構造や特性によるもので、軽量なモデル(例:MobilenetV2)などは計算が少ないため、NPUの性能を十分に活かせず、結果としてCPUの効率的な処理が優位に立ったからだと思われます。一方、ResNet18やVgg13のような大きなモデルはCPUと比べて比較的高速になる傾向にありました。
最新のモデルでの評価
AIモデルのパラメータ数と推論速度の関係を比較的新しいモデルであるconvnextをベースに比較してみました。 比較に使用したモデルは以下で、推論エンジンはOpenVINOを使用しています。
比較モデル
- convnext_small
- convnext_base
- convnext_large
パラメータ数と推論速度の関係
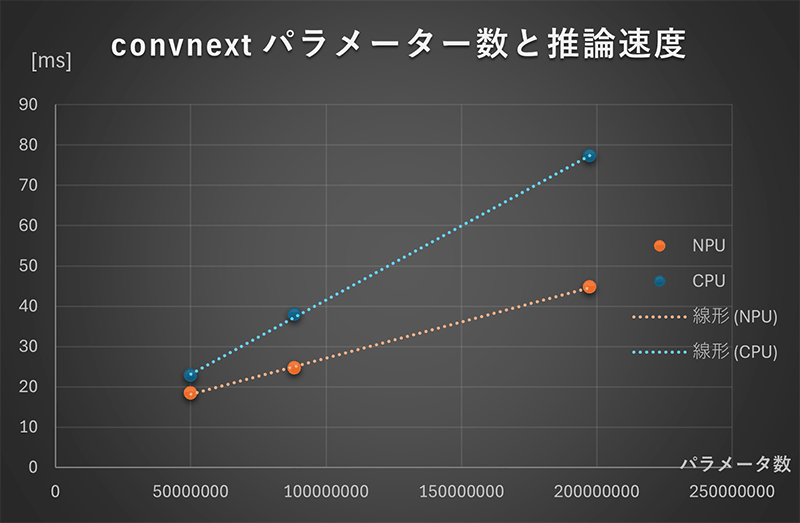
NPU、CPU共にパラメータ数と推論にかかる時間はある程度比例関係にようですが、パラメータ数が多くなるほどNPUを使う恩恵が大きくなるようです。
convnext v2はNPUを使うと遅くなる??
convnext
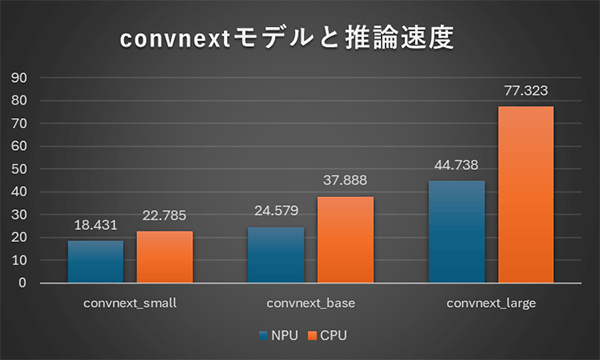
convnext v2
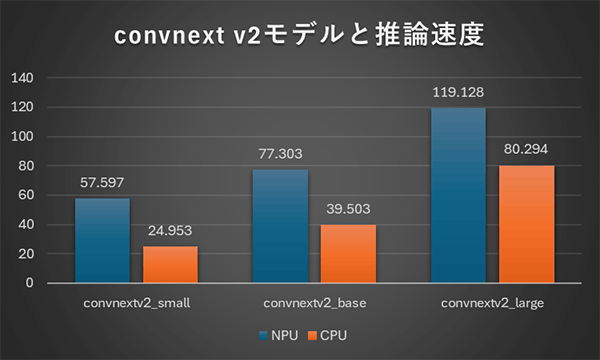
上記の左はconvnextモデル、右はconvnext v2モデルに対する推論速度の結果になります。CPUでの推論はconvnext、convnextv2共にそれほど違いはないですが、NPU推論時間はv2になると大幅に増加しています。
モデルには以下のような違いがありましたが、OpenVINOが最適化に対応していない処理があるのでしょうか?
- ONNXモデルのopsetとして、v2ではAbs, ReduceSumが増えている
ai_inference_device_benchmark
この記事で紹介したベンチマークテストは、弊社がOSSとして公開しているものです。
リポジトリはこちらからご確認いただけます:
https://github.com/ispcojp/ai_inference_device_benchmark
このリポジトリは、様々なデバイスでCNNなどのAIモデルを計測した結果を集め、デバイス間で公平な比較ができることを目的としています。 現在対応しているフレームワークは、Pytorch、ONNX Runtime、OpenVINOであり、CPU、GPU、NPUを使用したベンチマーク実行が可能です。
お手持ちのデバイスでベンチマークを実行し、その結果をPR(プルリクエスト)として共有していただけると嬉しいです!
終わりに
今回の検証に使用したCore Ultra7 265KFに搭載されているNPUの計算能力は13TOPSなのですが、実はCPUでもほぼ同等の計算能力(TOPS)を持っています。
ただし、得意な処理内容による違いがあり、重いモデルを実行するとNPUの処理速度の優位性が顕著に現れます。 また、CPUの計算リソースを温存しつつNPUに計算を任せられる点は大きなメリットかなと思いました。
Copilot PCの要件である40TOPS以上の性能を持つシステムであれば、さらに高速な処理が可能なのでいつかCopilot PCでも試してみたいですね。