
2016年夏に販売開始されNVIDIA Pascal世代の最強のGPU、NVIDIA TITAN Xがついに日本上陸です。
これまで、Pascal世代ではGeForce GTX 1080がトップだったのですが、NVIDIA TITAN Xはどれくらい機能差があるのでしょうか?ざっくりまとめ&ベンチマークしてみました。
ハードウェアスペック
GeForce GTX 1080、NVIDIA TITAN Xのカタログ値からいくつかの項目を比べてみました。(参考のため、Maxwell世代のGeForce GTX TITAN X も併記しています。)
| モデル | Memory [GB] |
単精度浮動小数点演算性能 [TFLOPS] |
Memory Bandwidth [GB/s] |
|
|---|---|---|---|---|
| Pascal | NVIDIA TITAN X | 12 | 約11 | 480 |
| GeForce GTX 1080 | 8 | 約8.9 | 320 | |
| Maxwell | GeForce GTX TITAN X | 12 | 約6.6 | 336.5 |
メモリ量は1.5倍、floatの計算速度の指標である単精度浮動小数点演算性能は1.25倍になっていることがわかります。また、メモリ量だけではなく、転送速度も1.5倍と高速化されています。
Pascal世代の1つ前であるMaxwell世代で最高性能であったGeForce GTX TITAN Xと比べても、大幅に機能強化されていることがわかります。
ベンチマーク
早速ベンチマークしてみましょう。普通はGPUのベンチマークだとゲームを動かしたりするのですが、ISPならではということで、もちろん題材はDeep Learningです。
実験1: GoogLeNet
まずはさくっとGoogLeNetで評価してみました。
Deep Learningの処理時間は1 epochの実行時間がわかれば基本的に掛け算で見積もれるため、ImageNetを1 epochやってみました。1 batch動かせばよいという話もありますが、念のため1 epochです。また、どれ位のBatch Size数を動かせるか試してみました。
評価条件
- DataSet: ImageNet2012、画像サイズは224 x 224 x 3(RGB)。
- Middleware: Caffe
- epoch数: 1
結果(実行時間 [min])
| モデル | BatchSize | |||
|---|---|---|---|---|
| 32 | 64 | 80 | 96 | |
| NVIDIA TITAN X | 56 | 50 | 49 | 49 |
| GeForce GTX 1080 | 72 | 66 | NA | NA |
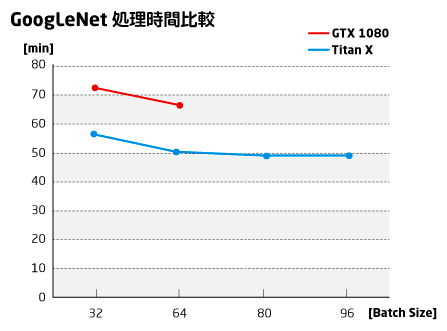
GTX 1080ではBatch Size 64までしかメモリに乗りませんでしたが、TITAN Xは96まで乗りました。メモリ量が1.5倍になっているのが如実に効いています。速度も1.4倍位になっているのがわかります。
一方、Batch Sizeのサイズの違いはそれほど実行時間に影響しないことがわかります。むしろ、32の方が遅くなりました。
実験2: ResNet
次に、ResNetを使って評価を行ってみました。
ResNetは2015年のILSVRCでトップを取った手法で、ImageNetのデータセットでは初登場時は152層、最近の研究では200層という深いネットワーク構成が可能です。CIFAR10というデータセットでは1001層(!)でも学習に成功しています。
元論文によると、200層のResNetは8枚のGPUを使って3週間かけて学習させたそうです。Titan X 1枚ではどれくらいになりそうでしょうか?
また、こちらはどれくらいのBatch Sizeが可能かという観点で実験してみました。
評価条件
- DataSet: ImageNet2012
- Network: ResNet。152層及び200層
- Middleware: Caffe
結果(バッチ数)
搭載できたバッチ数で評価しています。トレーニング時のバッチ数とテスト時のバッチ数(括弧内)となっています。
| モデル | レイヤ数 | |
|---|---|---|
| 152 | 200 | |
| NVIDIA TITAN X | 16(8)batch | 10(4)batch |
| GeForce GTX 1080 | 8(8)batch | 4(4)batch |
さすがにどちらでもResNet 200もメモリに乗りますが、対応可能なBatch Sizeが異なります。
TITAN Xはtrainに10バッチ乗せることができました。
結果(実行時間)
時間の都合上1 epochの実行時間ではなく、100 iterationでの実行時間を計測しました。また、そこから1 epochあたりの計算予測時間を計算してみました。
| モデル | 100 iterationあたりの処理時間 [sec] | 1 epochでの予想時間 [hour] |
|---|---|---|
| NVIDIA TITAN X | 32 ※batch size 10 | 8.9 |
| GeForce GTX 1080 | 26 ※batch size 4 | 18 |
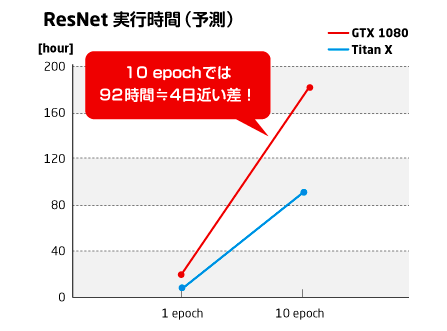
表中の「1 epochでの予測時間」ですが、100万枚の処理で1 epochとして算出しています。机上の計算ですが、倍以上の性能さが得られました。実際に学習させる際は数十epoch実行するため、実時間でいうと日・週の単位で効いてきます。TITAN X の本領発揮というところでしょうか。
まとめ
メモリ・計算速度共に大幅に進化したNVIDIA TITAN XによりDeep Learningの計算が一段と高速化されたことを確認できました。
実験結果からの予想時間ではありますが、ResNet 200では1 epochあたりの速度がGeForce GTX 1080に対し倍以上高速化され、ハードウェアの性能比以上の効果が見込まれます。