弊社では、この2年ほどDeep Learningを注力事業として取り組んでまいりました。Deep Learningで良い結果を出すにはさまざまなノウハウがあり、最先端の研究へのキャッチアップも含めてお手軽に結果を出せるツールとはとても言いがたいのが現実です。その分、私たちも皆様がお持ちのビッグデータを元に付加価値を創出していくところでお手伝いができておりまして、ビジネスになっております。
一方、Amazon や IBM, Microsoftといった巨大企業は、データは持っている一方データサイエンティストや機械学習用コンピュータといったリソースは確保できていない組織向けに手軽に使える機械学習サービスを提供しています。これらのサービスは、組織として機械学習のアルゴリズムやノウハウを持っていなくても、データを用意して学習させればそれなりの結果をお手軽に出してくれるという強みがあります。
そのような機械学習サービスの中から、今回はAmazonが提供している機械学習サービス、”Amazon Machine Learning”を使ってみました。
by Tetsuro Kitajima 2016/6/2
今回Amazon Machine Learningを使ってみるにあたり、私たちでは以下のような問題を設定しました:気象庁が提供している大阪の気象データから気温、降水量、日照時間、湿度、それに日時を使って、関西電力が提供している関西圏における消費電力量のデータを予測する、という回帰問題。使ったデータは全てオープンデータとして公開されているものです。
今回の実験では2015年4月1日から2016年3月31日までに測定された1時間ごとのデータを用い、ランダムに選んだ半分のデータを訓練用、残りを試験用に分割しました。
手順
Amazon Machine Learningを使う手順は、以下の通りです。
- データをAmazon S3(ストレージ)かAmazon RedShift(データウェアハウス)にアップロードする(SDKで提供されるAPI経由で実行する場合、Amazon RDS = データベースのMySQLも利用できます)
- 登録したデータを読み込み, DataSourceとしてAmazon Machine Learningが利用可能な形に変換する。この段階で、Amazon MLが各カラムの形式や欠測などを精査します。
- DataSourceをもとに学習し、ML Model(回帰器・判別器)を作成する。
- Evaluation(評価)を行い, 作成したML Modelを評価する。
- 問題なければBatch PredictionやRealTime Predictionを通じてML Modelを活用する
これらの段階はSDK経由でも実行できますが、まずはWebコンソール経由で手順を踏んでみました。
データを作ってアップロード
Amazon S3にアップロードするデータは、ごく普通のCSVで問題ありません。先頭行に列の名前を入れておけば、自動で読み取らせることができます。また、正解ラベル/値が先頭のカラムに置かれている必要はありません。
Amazon Machine Learningではデータのうち一部を訓練用、一部を試験用に取り分ける仕組みが実装されていますので、手軽に使いたいときは全データをまとめたCSVをアップするだけで訓練・試験の取り分けを完了できます。他の手法との比較など、データセットの分割をきちんと制御して機械学習に取り組みたいならば、訓練用データと試験用データを別々のCSVにアップロードしてDataSourceを作ることもできます。
今回は、弊社内でのDeep Learningとの比較を意図して、訓練用データと試験用データを別のCSVとして作成しました。
回帰器・判定器の作り方
といっても、ユーザサイドで工夫できることはあまりありません。データセットを正しく指定して訓練を指示すれば、あとはAmazon Machine Learningが良い感じにやってくれます。自力でやろうとするとたくさんのノウハウや経験が必要な機械学習を手軽に運用できることがAmazon Machine Learningの身上。逆に言うと、あまり凝ったことはできませんが、判定問題であればEvaluationを行った後に、判定の閾値を変えることができます。
例えばデータから特定の属性を持つかどうかを判定する問題で、False Positive(=実際には属性を持たないのに、機械学習は持つと誤判別する場合)は許容するがFalse Negative(=実際には属性を持つのに、機械学習は持たないと誤判別する場合)は許容しない、といった目的に合わせて閾値を調整できます。
結果と評価
ML Model をEvaluationした結果を以下に示します。
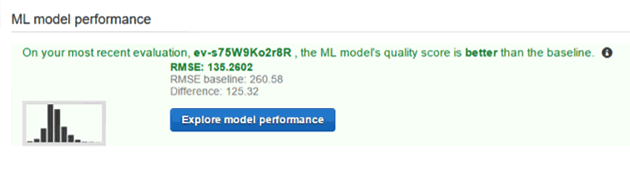
このくらいの結果しか見えませんので、凝った評価をしようとすると色々無理があります。
本格的なn-fold cross-validationもサポートしていません。
Amazon Machine Learningは凝ったことができないわけですが、得られる結果はDeep Learningと比べてどうなのでしょうか?そこで、弊社内ではまいどおなじみxchainerでDeep Learningした結果と比べてみました。
Deep Learning側では、隠れ層5層を持つニューラルネットで学習を行いました。最終層以外の各層にReLUを仕掛けてありますが、それ以外は特殊なことは仕掛けておらず、ごくプレーンなDeep Learningを実行しました。
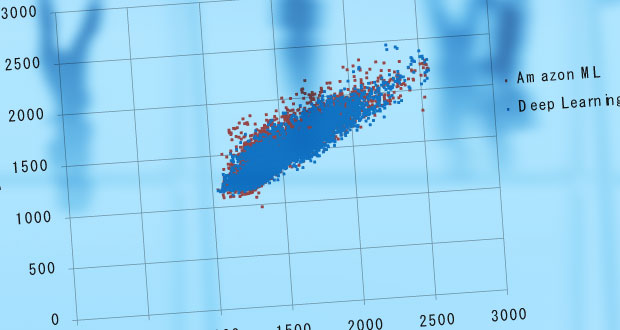
結果のグラフは以下のとおりです。
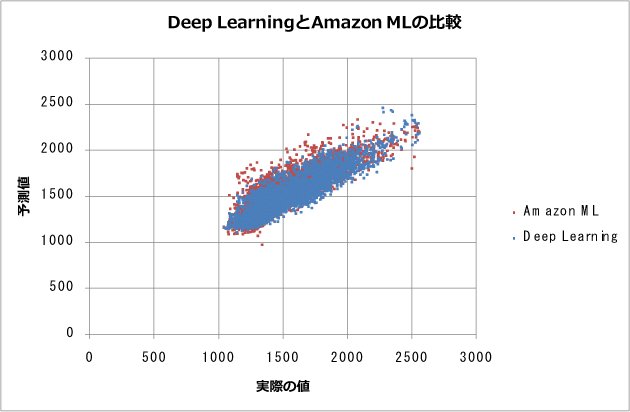
赤点がAmazon MLの結果, 青点がDeep Learningの結果です。グラフで見ると、Amazon MLとDeep Learningは点が重なっており、おおむね同等の結果を示しているように見えます。
より小さな差異を見るために、R^2(相関係数)やその他のパラメータで見てみましょう。
| Amazon ML | Deep Learning | |
|---|---|---|
| R^2 | 0.73 | 0.79 |
| 回帰傾き | 0.72 | 0.74 |
| 回帰切片 | 449.70 | 374.35 |
| 最小残差 | -693.27 | -460.58 |
| 最大残差 | 602.14 | 438.23 |
R^2と残差の分布幅で判断する限り、Deep Learningのほうが少しだけ良い結果を示しています。
コスト
まずは金銭コスト。この程度の規模のデータセットだと、新規のデータセットをアップロードして、訓練データセットで機械学習かけて、試験データセットで回帰して評価する、といったサイクルを1回回すごとにざっくり0.5~1ドル程度のコストがかかります。日本円だと50~100円程度です。
次に、時間コストについて。今回の程度のデータセットだと、Amazon Machine Learningで訓練・評価には1時間もかかりません。データをS3にアップロードしてDatasetを作成、訓練開始を指示してコーヒー1杯飲んでいるうちに回帰器が出来上がります。
Deep Learningの場合は自力でネットワークを構成して試行錯誤する必要があり、今回の結果を出すまでに2時間くらいはかかりました。
まとめ
Amazon Machine Learningを使ってみて、データを投入すれば簡単にそれなりの結果が出ることには驚きました。もちろんAWSの独特なノウハウ、概念を知る必要はあります。実際やってみてその学習コストがそれなりに高かったのは事実です。ですが、AWSを知っていて扱えるエンジニアは世間にいくらでも確保できます。機械学習エンジニアやデータサイエンティストを見つけるよりは、AWSエンジニアを見つけてAmazon Machine Learningを使うほうがよほど簡単でしょう。
Amazon Machine Learningではわずかなお金と大量の数値データさえあれば容易に機械学習を自分のシステムに取り入れることができます。一方, Amazon Machine Learningはできることが限られ、数値データから結果を得る判別問題、回帰問題程度しか解けません。例えば数値データではなく画像データを持っている企業が機械学習で価値を創出しようとすると、Amazon Machine Learning単独では完全に力不足になります。アルゴリズムがブラックボックスなので、学習プロセスや結果の改善も難しい作業になります。
これらの経験から、Amazon Machine Learningは質の良い数値データを大量に持っているけれどデータサイエンティストや機械学習に通じたエンジニアは確保できないような環境、組織がちょっとした判別結果を機械学習で得るには向いていると感じました。