今回の記事では、音声データのDeep Learning(以下DL)に挑戦します。
この記事で取り組む課題は技術的実験と位置づけ、先日の記事(xchainerをGPU対応させてみた)で紹介したGPU対応版xchainerの実戦投入もあわせて、ふだん弊社のプロジェクトでは使っていない道具立てを中心に取り組んでみました。
by Tetsuro Kitajima 2016/4/7
実験のターゲット
今回の実験では、「ダメ絶対音感」の実装を目指すことにしました。
「絶対音感」とは音を聞いて即座にその音の名前が分かるという能力のことなのですが、そのパロディーで「ダメ絶対音感」というスキルがあります。アニメや吹き替え映画やゲームといったコンテンツで声を聞いたらその声を当てている人が誰だか分かるというものです。
IT業界は一般的にオタクが多い業種と言われていますが、弊社は珍しくオタクが少数派です。でも胸を張ってこんなオタク色フルパワーな実験をしているあたり、弊社の自由さをお楽しみください。
技術的には、ダメ絶対音感とは即ち声優に限られた話者認識です。話者認識技術自体はガウス混合モデル(GMM)をもとにサポートベクターマシンによる機械学習を適用する手法(GMM-SVMなど)や、実ノイズが含まれる音声に対しては各種の特徴量から線形判別分析(LDA)で得られた因子をSVMによる機械学習やコサイン類似度といった指標で判別する、といった手法が実用的に知られています。今回は弊社らしく、ディープラーニングで話者認識/ダメ絶対音感に取り組みます。
データの収集
今回、分析に使う音声データはアマチュア声優(ボイスコ)の皆様にご協力をいただきました。業務案件だと商用データベースやオープンデータ、お客さまが採取したデータや、場合によってはYouTube等からのクローリングでデータを集める わけですが、今回は実験ですのでそれなりに素性の良いデータ を使いたいこともあり、アマチュア声優さんにご協力いただきました。
……第一線で活躍しているプロの声優さんのサンプルデータ?そんなもの、コンテンツビジネスでもやっていない限り普通は手に入りません。ましてや実験レベルで使えるデータでは絶対にあり得ません。本当は使ってみたいですけどね!
今回協力を頂きましたのは、以下の4名です。
春野まつり さま ( http://sorasorausagi.aikotoba.jp/ )
城野 晴歌 さま ( http://koebu.com/user/seikakino )
姫月 夢乃 さま ( http://koebu.com/user/252528280×0 )
上条 佑人 さま ( http://coolstyle.but.jp/ )
皆様から演技や語りの音源をたくさん頂きました。ありがとうございます!
頂いた音源には、前処理をかけてDLに学習させる特徴量に変換していきます。
データの前処理&入力データ
データの前処理は以下のように行いました。
- すべての音声ファイルを16kHz, 16bit エンコーディングのWAVファイルに変換
- 得られた音声の全体で、0.1秒以上の静音区間をカット
頂いた音声データに前処理を施した段階で、利用できる音声データの分量は以下の通りとなりました。
- 春野まつり さま:26,802 kBytes
- 城野 晴歌 さま:18,935 kBytes
- 姫月 夢乃 さま:60,116 kBytes
- 上条 佑人 さま: 6,333 kBytes
2009年の著作権法改正で、情報解析のための複製は解析用に提供されているデータベータベースを除いて著作権の縛りを受けずにできるようになりました。規定改正の背後には、情報解析のための複製を自由に許しても著作権ビジネスには大きな影響はないだろう、という推測があるようです。
実際の業務の場で出会うデータは品質が良いとは言えないことも多く、まずはデータを綺麗にする、使えないデータを切り捨てるところから泥臭い作業が待っています。
今回の実験で用いる入力データは、FFT(高速フーリエ変換)で得られる周波数領域のスペクトルを採用しました。音声系の機械学習ではMFCC(メル周波数ケプストラム)やそれに類する情報量を使うことが多いですが、今回はよりシンプルな情報量で結果を出せないか試す意図もあり、FFTで得られるスペクトルで実験しています。
DLは本来特徴量を自力で見つけ出せることに優位性があると言われていますが、実際に手を動かして業務に活用している経験からすると、元データから単純な演算処理で得られる特徴量はともかく、FFTや共分散・相関係数のように複雑な演算が必要な特徴量についてはDLの入力として最初から与えてあげたほうが学習を進めやすいです。
データを作るための前処理は以下の手順で行いました。
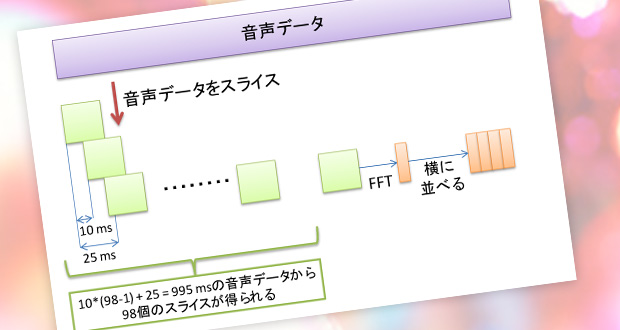
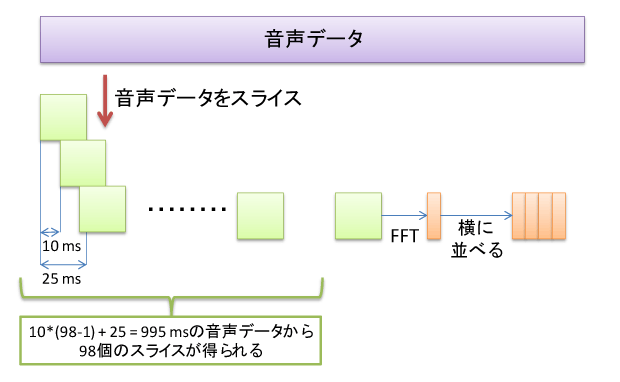
- 10 msずつスライドして取得した25 ms の音声データをFFTで30次元ベクトルのスペクトルに変換
- 得られた30次元のベクトルを98本並べる。10 msずつスライドさせたベクトルを98本並べるので、1つの入力特徴量としては995 ms分の音声データを用いることになる。
- 結果、入力データは30*98次元の量となる。
以上の前処理によって得られたデータは、ランダムに半分に分割して一方を学習に投入するデータ、もう一方を判定用のデータとして取り扱うことで、学習に投入したデータと同じものを判定用に使うことを避けられます。
なお、今回はサンプリングレートを16kHzに落とした音源で分析をしておりますので、シャノンのサンプリング定理に従い8kHz以上の領域は切り落とされています。ごく稀に20kHzを上回る超音波領域の成分を含んだ声を出す声優さんがいまして、プロ声優の世界では金田朋子が有名ですが、アマチュア声優でも複数人いることが確認されています。彼女たちの声を分析に供する場合、収録機材から分析過程までハイレゾ音声に対応できるワークフローの採用を検討する必要があるかもしれません。
DLフレームワークの選定
DLの発展・流行に伴い多くのグループがDLのフレームワークを開発しており、最近ですとGoogleの開発したTensorFlow, Microsoftの開発したCNTK, Preferred Networksの開発した国産フレームワークChainer, UC Berkeleyが中心になって開発したCaffeといったツールが生まれてきました。DLのアプリケーションを1から作るという選択はそれ自体をビジネス価値や研修の目的にする意図でもなければ車輪の再発明になって業務現場ではありえませんので、まずはどのフレームワークを使うか選定する必要があります。
弊社では caffe を使うプロジェクトが多いのでcaffeの経験を持っている人は多いのですが、実験企画でふだんと同じものを使っても新しいスキルがつかないし、なによりcaffeは入力データの取り扱いに色々と特別なノウハウが必要です。今回は先日の記事で公開したxchainer GPU版を実地で使う意図も兼ねて、chainerベースでDL学習と評価を進めました。
chainer / xchainer / scikit-learn
今回の実験に使ったフレームワークを紹介します。
scikit-learn とは、 python向けの機械学習ライブラリです。いろいろな種類の機械学習を統一されたインタフェースで扱えるように整備していて、例えばAdaBoost, 線形SVM, RBF SVMといったスタンダードな手法なら簡単に使えるようになっています。また、Confusion Matrixの生成や各種評価指標の算出なども容易です。
chainerの名前は機械学習/DLに取り組まれている方なら聞いたことある方も多いでしょう。先述の通りPreferred Networks社が開発したDL向けのフレームワークで、ネットワークの構造を直感的にプログラマブルに記述できる特徴があります。
xchainerは、先日の記事 (xchainerをGPU対応させてみた) でも取り扱いました通り、chainerをscikit-learnの一部として扱えるようにするラッパーライブラリです。元々はリクルートテクノロジーズ社がオープンソースで公開したCPU対応ライブラリですが、先日の記事で紹介した通り弊社にてGPU対応を実装しましたので、そのバージョンを使っています。
scikit-learn / xchainerを使うことで、caffeやオリジナルのchainerでは一苦労のかかる作業になるCross Validationを容易にこなせますし、scikit-learnが持っている学習結果評価系のロジックを使うとPrecision, Recall, F1-Scoreといった評価のための指標も容易に計算できます。
学習&検証
いくらかの試行錯誤の結果、以下のようなFully-ConnectedのDeep neural networkにて学習を行いました。
入力データは先ほど説明しました通り前処理済みのデータから半分をランダムに選んで用い、30 * 98 次元、バッチサイズは32とし、300 epochs の学習を行いました。
| 層の種類 | 入力次元 | 出力次元 | Dropout | 活性関数 | |
|---|---|---|---|---|---|
| 1層目 | Fully-Connected | 30 * 98 | 4096 | あり, ratio = 70% | ReLU |
| 2層目 | Fully-Connected | 4096 | 1024 | あり, ratio = 60% | ReLU |
| 3層目 | Fully-Connected | 1024 | 256 | あり, ratio = 50% | ReLU |
| 4層目 | Fully-Connected | 256 | 64 | あり, ratio = 40% | ReLU |
| 5層目 | Fully-Connected | 64 | 64 | あり, ratio = 40% | ReLU |
| 6層目 | Fully-Connected | 64 | 4 | なし | なし |
この学習・検証実験は学習データと検証データの組み合わせを変えて10回行い、Precision, Recall, F1-Scoreについては平均値・標準偏差を求め、Confusion Matrixについては10回の合計を求めました。
10回の学習・判定によって得られた結果をあわせた成績は以下の通りとなりました。数値の表記は 平均値 +/- 標準偏差 としています。
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 春野まつり | 74.10% +/- 0.57% | 74.70% +/- 1.16% | 74.10% +/- 0.57% |
| 城野 晴歌 | 61.60% +/- 1.17% | 63.40% +/- 2.22% | 62.30% +/- 1.49% |
| 姫月 夢乃 | 83.10% +/- 0.57 | 84.70% +/- 0.67% | 83.80% +/- 0.42% |
| 上条 佑人 | 36.00% +/- 1.76% | 24.10% +/- 2.69% | 28.90% +/- 2.02% |
Precisionは日本語では適合率、ある人の声と予測したうちで結果が正しかったものの割合です。Recallは日本語では再現率、ある人の声のうちで予測結果が正しかったものの割合です。数式で表現すると、以下の通りです。
| 真の結果 | |||
|---|---|---|---|
| A | B | ||
| 予測結果 | A | TP | FP |
| B | FN | TN | |
Precision = TP / (TP+FP), Recall = TP / (TP + FN) で与えられます。
次に、10回分の学習・判定の結果として得られたConfusion matrixを合わせた表を紹介します。
| 判定結果 | ||||||
|---|---|---|---|---|---|---|
| 春野まつり | 城野 晴歌 | 姫月 夢乃 | 上条 佑人 | 合計 | ||
| 真の話者 | 春野まつり | 17882 | 1143 | 4931 | 48 | 24004 |
| 城野 晴歌 | 1068 | 10801 | 3314 | 1811 | 16994 | |
| 姫月 夢乃 | 5125 | 2492 | 45889 | 608 | 54114 | |
| 上条 佑人 | 84 | 3093 | 1142 | 1379 | 5698 | |
この表を見ると、上条さんの声を判定させると城野さんと間違えるパターンが多いようです。人間が聞けばこの2人を間違えることはないような気もするので、ディープラーニングが人間っぽくない部分の現れなのか、それとも上条さんのデータ不足で本質的に判定が難しい状況なのか、どちらなのでしょうか。逆に、比較的隔たりが小さいように見える春野さんの声と上条さんの声を間違えることがほとんどないのは興味深い結果。
姫月さんの声はデータ量が多いこともあり他の人とはあまり間違えないのですが、その中では春野さんと間違えることが多いようです。春野さんの声は、城野さんや上条さんの声よりは姫月さんの声との隔たりが近いので、それなりに妥当なところです。
結論と今後
まず、データをご提供いただきました皆様には深く御礼を申し上げます。
今回はxchainerを使って、DLベースでのダメ絶対音感の実装に挑戦しました。今回の系では、DLダメ絶対音感を精度80%程度で実現するには前処理後の音声にして一人あたり30分程度のデータが必要なようで、音声データ量が少ない方の予測精度が落ちました。
実際の業務でも、データ量不足に悩む局面は多いです。今後ビジネスでDLに取り組まれる方は、データの確保について手厚く取り組まれることをお勧めします。
今回の記事に向けた実験はこれで終わりですが、今後もConvolutionの適用, 各種先鋭的な手法の適用, さらにはCross Validation手法の深化をはじめとしたモデル評価手法の深化といったテーマが考えられます。これら新規テーマの実験については、追加のデータを入手した上で継続的に取り組んでいきたい所存です。