ISPでは、Deep Learningを用いて物体をダイレクトに検出することに成功しました。
今までのDeep Learningを用いた物体検出(R-CNN)では、物体らしい領域を検出したうえで判別器(CNN=Convolutional Neural Network)にかけて物体を検出する方法がとられていますが、私達は物体検出を「Deep Learningの回帰問題」ととらえて学習を工夫することにより、カメラで撮影した映像から物体の位置・大きさをダイレクトに検出させました。これを『ダイレクトなR-CNN』と呼んでいます。
本記事では、この『ダイレクトなR-CNN』について説明します。
by Nagasawa Kazuki 2015/12/19
検出アプリケーションの様子
課題設定
ISPでは、宇都宮大学尾崎研究室のグループとの共同研究という形で「つくばチャレンジ2015」に参加しました。
今回は尾崎研究室の自律走行ロボットが撮影した画像をお借りし、つくばチャレンジ看板の位置・大きさの検出を行いました。

学習データ
Deep Learningの学習では大量の学習データが必要となり、準備に非常に手間がかかることが多いです。今回も本来ならば「つくばチャレンジ2015」での看板が写っている画像が大量に必要です。
しかし、今回はISPの高品位画像合成技術「ROBUSKEY」を用いることにより大幅な省力化を実現しました。
学習データ生成については、別の記事にて紹介しています。
Deep Learningで用いるデータを「生成」してみた
手法
従来手法
従来の物体検出の手法として単純なものでは、入力画像を網羅的にラスタスキャンし「あり・なし」を判定することで行います。
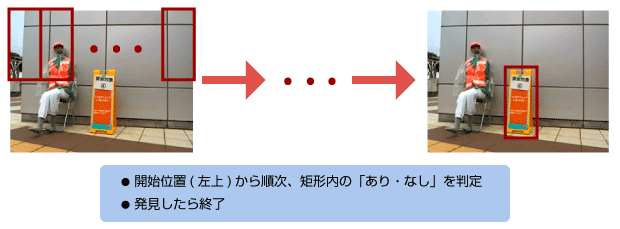
この手法の場合、一回の判定は「あり・なし」の二択で単純なため高速に行うことができるのですが、網羅的なラスタスキャンの方に時間がかかることが欠点です。また、「近くの大きい看板」「遠くの小さい看板」を見つけるために判定を行う領域を変えたり、網羅的な判定を行うための領域のスライドの仕方を工夫したりと、ラスタスキャンを取り入れる方法にも工夫が必要です。
『ダイレクトなR-CNN』
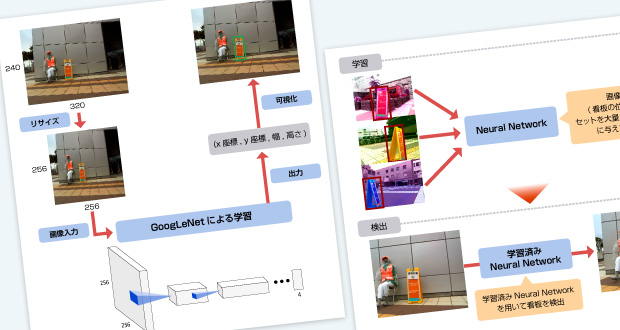
今回の手法では、まずNeural Network (=NN)に大量のデータを学習させます。そして、学習を行ったNNを使い、実際の映像から検出させます。
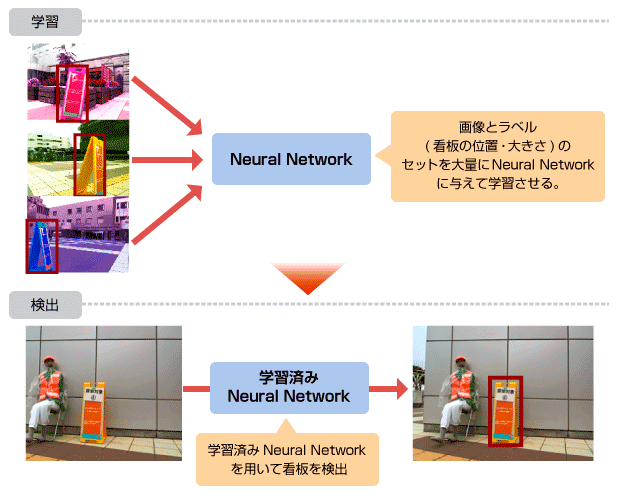
この手法では、NNへの学習を行うのに時間がかかります。
しかし、検出に関しては、従来手法で行っていた「ラスタスキャン+検出」の処理が「NNでの検出」1回で行うことができるので、非常にシンプルです。また、大量のデータを与えて学習さえしてしまえば、検出には学習済みNNを組み込むだけで検出が可能です。
Neural Networkへの学習と検出
学習
学習には看板が写っている大量の画像が必要となります。ISPの高品位画像合成技術「ROBUSKEY」を用いて看板画像と背景画像を合成し、更に画像処理を合わせて大量の学習用画像を生成しました。
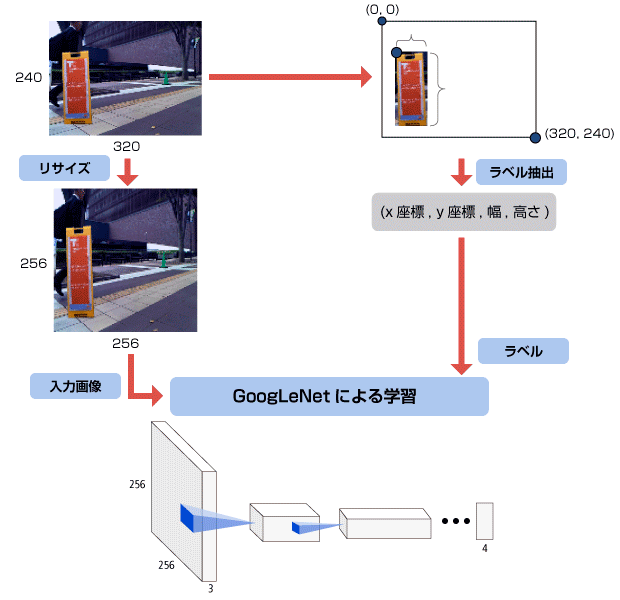
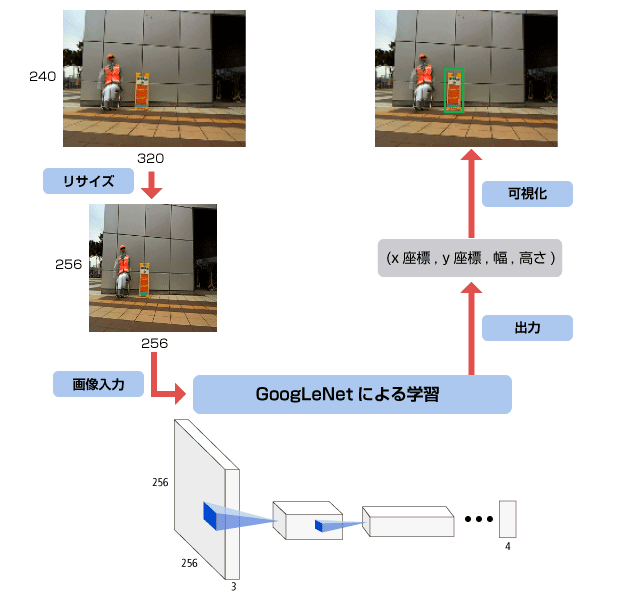
また、各画像に対して正解ラベルが必要です。今回の課題では、「画像の左上を起点 (0, 0) とした時の看板左上x座標・y座標」「画像の上の看板の幅・高さ」の4つの数値をラベルとして与えました。
このようにして用意した画像とラベルのセット約40,000データをNNに与えて学習させました。
今回用いたNNは、2014年のILSVRC(一般画像認識の有名なコンペティション)で成果を出したGoogLeNetを使用しました。
ただし、出力のニューロン数はラベルの要素数に合わせて4としました。また、つくばチャレンジ画像は340 × 240ピクセルなのですが、GoogLeNetの入力に合わせて256×256ピクセルにリサイズしてNNに入力しました。
検出
学習によって最適化されたNNを組み込んだ検出器を利用し、Webカメラで撮影した320×240ピクセルの画像から看板を検出しました。
検出では、撮影した320 × 240 ピクセルの画像を 256 × 256 ピクセルにリサイズした上で学習済みNNに与えることで、4つのニューロンの値を得ます。この値が元の320×240ピクセル画像での看板の位置・大きさである4つの値 (左上x座標, 左上y座標, 幅, 高さ) となっています。
実行
Webカメラが写した映像内の看板の位置・大きさを検出するアプリケーションに学習済みNNを組み込み、動作させました。
検出アプリケーションの様子
まとめ
今回はISPの技術を用いて大量に効率よくデータ生成を行うことができたこともあり、つくばチャレンジのコース以外 (例えば社内) での検出や、目の前の障害物に邪魔されない検出など、当初の想定を超える検出ができたことには作成していて非常に驚きました。
今回は時間の制約が大きく、NNには成績が良いとされているGoogLeNetを利用しました。確かに良く学習し、検出してくれたのですが、GoogLeNetは非常に巨大であるため、
- ハイエンドスペックのGPUでも検出には0.2秒程度かかっている。 (動画で矩形描画が遅れているのはこの検出時間のため。)
- 検出に利用するNNをGPUメモリ上に展開するため、非常に多くのメモリが消費される。
と、デメリットも見えてきています。
つくばチャレンジは自律走行ロボットのコンペティションですが、自律走行ロボットに組み込むためには、これらの問題は乗り越えなければならないものです。今後に向けて、更に問題を追求していきたいです。
その他技術的内容について
実行環境
学習・検出アプリケーションの実行環境は以下のとおりです。
学習用PC
| CPU | Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz |
|---|---|
| GPU | NVIDIA Geforce GTX 980 Ti |
| OS | Ubuntu 14.04 (LTS) |
| Python | 2.7 |
| CUDA | 7.0 |
| cuDNN | version 2 |
| Deep Learning Framework | Caffe |
検出アプリケーション用ノートPC
| CPU | Intel(R) Core(TM) i7-4720HQ CPU @ 3.60GHz |
|---|---|
| GPU | NVIDIA Geforce GTX 980 M |
| OS | Ubuntu 14.04 (LTS) |
| Python | 2.7 |
| CUDA | 7.0 |
| cuDNN | version 2 |
| Deep Learning Framework | Caffe |
学習誤差、学習状況の評価について
今回は学習誤差として二乗誤差を採用しました。NNが出力した4つの値と画像の正解ラベル(x座標, y座標, 幅, 高さ) の値に対して単純に二乗誤差を取り、学習を行いました。
10 epoch実行した学習データの誤差の推移状況は以下の通りです。早い段階から十分に学習できている様子でした。
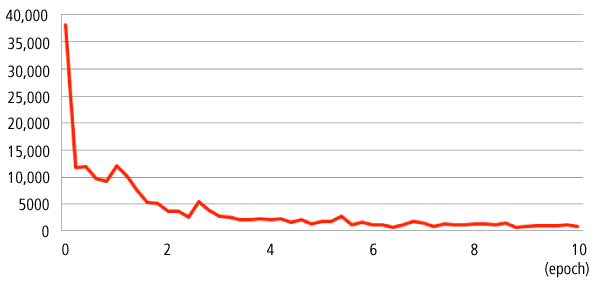
学習誤差について、正解ラベル(x座標, y座標, 幅, 高さ) に対してそのまま二乗誤差を取るだけで学習を行いました。今回はうまく行ってしまいましたが、本来は4つの値はそれぞれ違う定義の値 (前半2つは位置・後半2つは大きさ。更にそれぞれ定義域が違う。) なので、それに適した形の誤差を取るようにすることで、更に効率良い学習ができるかと思います。
また、学習状況について、今回はテスト用の画像を用いて学習中にテストを行いませんでした。これには上記の『二乗誤差でそのまま学習を進めた』ことに原因があり、いくらテスト画像で二乗誤差が下がっても、実際の画像の検出とは直接結びつかないことが想定できたからです。(二乗誤差が0に近くても、『大きさが合っているが位置がずれている』場合等あるため。)
この点においても、やはり本来のラベルの値の意味をしっかり理解し、それに適した学習を行うNNの定義をしていくことが重要だと思います。