JetsonTX1でHyper-QによるStreamを使用した並列動作を確認する機会があったため、確認手順や確認結果ご紹介します。
by Muneyoshi AMATSU 2016/8/9
「JetsonTX」とは
NVIDIA製の組み込みコンピュータです。ARM Cortex-A57、Maxwellアーキテクチャをベースとした256基のCUDAコアを搭載し、以下Compute Capabilityの表に示すように、Hyper-Q/DynamicParallelismをサポートしています。
| Architecture | Compute Capability | 特徴・機能 | 備考 |
|---|---|---|---|
| Kepler | 3.0 | 192 Cores/SMX | |
| 3.2 | Tegra K1 | ||
| 3.5 | Hyper-Q/DynamicParallelism | ||
| Maxwell | 5.0 | 128 Cores/SMM | |
| 5.2 | 96KB shared memory | ||
| 5.3 | Tegra X1, FP16 Support | JetsonTX1 |
(http://www.slideshare.net/NVIDIAJapan/1070-cuda より)

(http://www.nvidia.com/object/jetson-tk1-embedded-dev-kit.htmlより)
| OS/ミドルウェア | |
|---|---|
| OS | Ubuntu 14.04 LTS |
| CUDA | CUDA 7.0 for Jetson TX1 Developer Kit |
| OpenCV | OpenCV4Tegra 2.4.13 |
Hyper-Qとは
CPUからGPUにはグリッドという単位で実行を依頼しますが、CUDAにはストリームという概念があります。
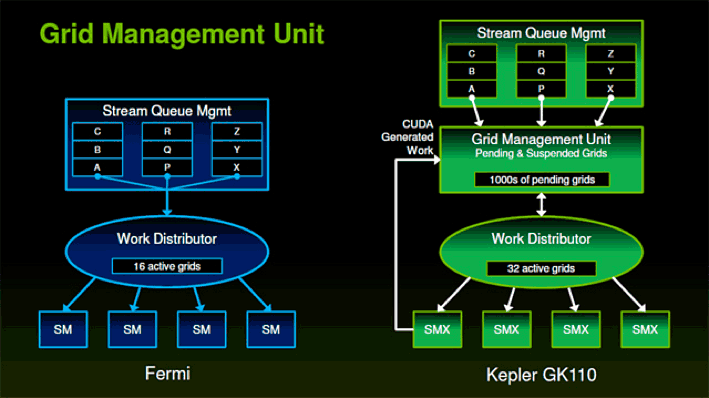
GPUがグリッド内のブロックをどのSMXに割り当て、それぞれのブロックをどのようにWarpに分割するかを担当するのがワークディストリビュータ(Work Distributor)というブロックです。ワークディストリビュータは実行を依頼されたグリッドに含まれるブロックの数や各SMXの負荷状態を考えて割り当てを決めます。
Fermi世代ではワークディストリビュータの入り口のキューが1つしかなかったため、処理性能のネックになりえましたが、Kepler世代では入り口が32本に拡張されることにより、並列実行できる可能性が高めることができるとされています。
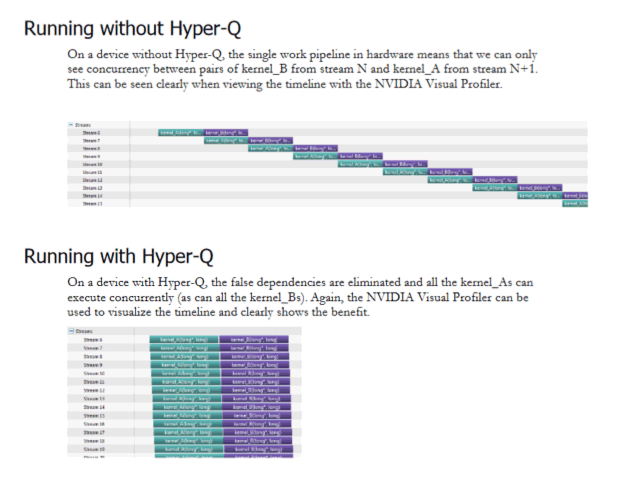
試してみたこと
NVIDIA社提供のHyper-QのサンプルプルグラムをJetsonTX1上でビルド・実行し、以下のような動作となるか実際に試してみました。
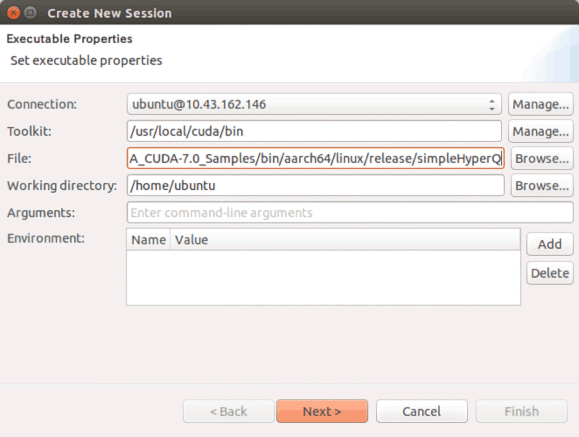
実測するプログラムはNVIDIA社から提供されているNVIDIA_CUDA-7.0_Samplesに含まれるsimpleHyperQというプログラムを使用します。(上記で使用されているプログラム)
実測方法について
JetsonTX1上ではnvvp(NVIDIA Visual Profiler)などのvisual profilerが使用できなかったため、PC上仮想環境のUbuntu Host PCからnvvpを起動し、リモートprofilingを行いました。
実測した結果について
以下のように最大4並列の動作しかしていないようです。
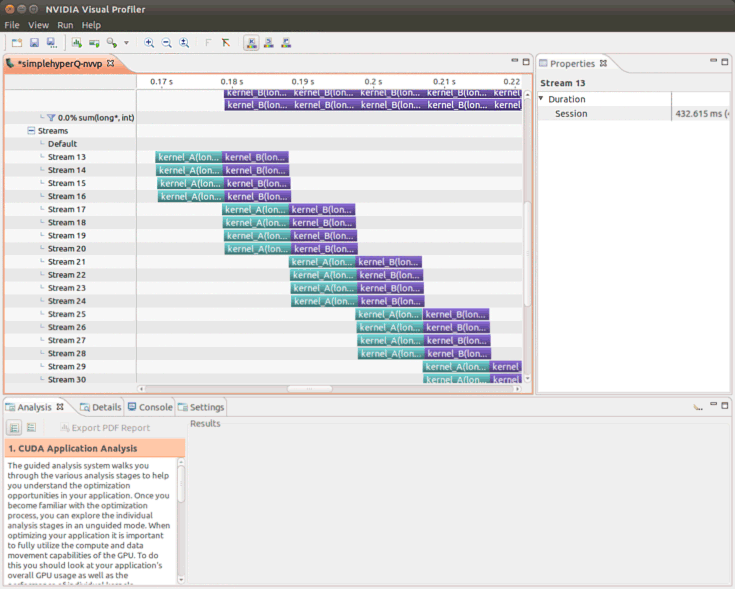
原因を調査したところ、CUDAには32スレッドの同一命令を32コアに割り振り並列実行するWARPという概念があり、1SMM上の128コアは 4つのkernelの発行しかできないことの影響かと思われました。(このプログラムでは1スレッドでカーネルを起動しています)しかし、ではなぜ256/32=8 並列でないのかと疑念が残ります。JetsonTX1固有の動作か切り分けるためにハイエンドGPU(GeForce GTX 980 Ti, Compute Capability 5.2, 128×22 CUDA Cores)で動作を確認したところ、8並列まで動作しました。(・・何がどう関連しているのかと頭を抱えてしまいました・・)
さらに調べたところ、実はCUDAには最大並列実行数を指定する環境変数があることが分かりました。
※実行環境にて、CUDA_DEVICE_MAX_CONNECTIONS=
なお、CUDA_DEVICE_MAX_CONNECTIONSを設定しない場合のデフォルト値は、JetsonTX1では4, GTX 980 Tiでは8であることが分かりました。つまり、JetsonTX1で4並列しか動作していなかったのはこの制限を受けているからでした。
実際に、JetsonTX1で8/16/32並列を順次指定して、4並列を超えてStreamが並列実行できることを確認しました。しかし、32並列を指定すると、以下のように今度は16並列で制限がかかることが分かりました。
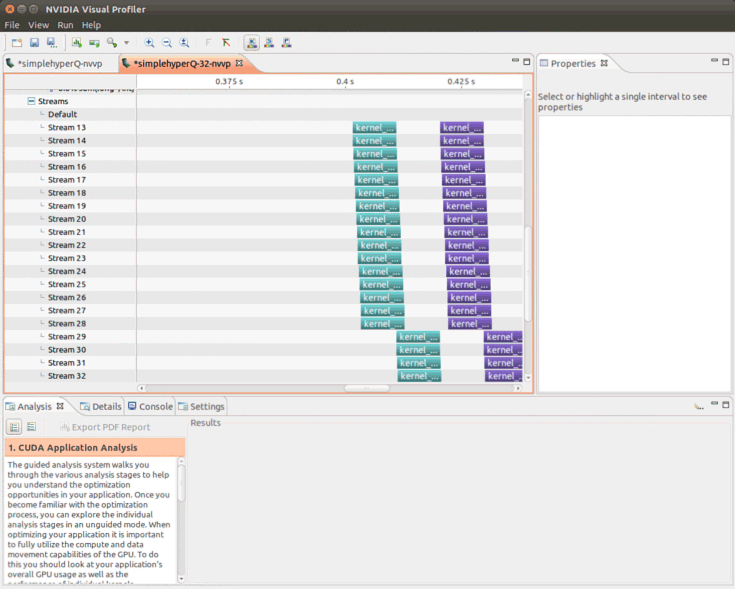
JetsonTX1固有の動作か切り分けるために先ほどと同様にGTX 980 Tiで動作を確認したところ、32並列で動作することが分かりました。
その後紆余曲折の末、以下のようにCompute Capability 5.3では Maximum number of resident grids per device (デバイス上に存在できる最大グリッド数)が32⇒16に変更になっており、JetsonTX1ではMAX 16並列実行できることがあるべき動作であることが分かりました。

補足として、JetsonTX1では32コアに割り振り並列実行するWARPのしくみにより8 並列が上限ではないかと検討途中に記載しましたが、実はそれはCUDAコアのH/W的な制限であり、S/W的には以下動作となることを記載しておきます。
- カーネルはタスクスイッチしながら動作するため、コア数による限界(最大8並列)は今回の件とは関係ありませんでした
- 実際にどの程度の処理速度が出るかはカーネルの処理内容次第です。8並列相当の速度しか出ない場合もあれば、16並列の速度が出る場合もあります。
さいごに
ある業務でJetsonTX1でCUDAを使用した並列実行プログラムの処理速度を計測する機会がありましたが、期待通りに動作しないことに悩まされていました。それで、そもそもsampleプログラムで動くのか?と試してみたら、動かなかった!という衝撃的な事実を発見してしまったのが今回の記事のきっかけです。CUDAに最大並列実行数を指定する環境変数CUDA_DEVICE_MAX_CONNECTIONSがあるのであれば、とりわけHyperQ.pdfにこそ記載を追記すべきではないでしょうか。現在は記載が無いため、今回のように同じように困っている方がいるかもしれないので、色々調査した結果を共有させていただきました。ささやかな助けになれば幸いです。