ISPはデータ解析の技術をより磨くべく、平成26年データ解析コンペティションに参加しました。このコンペティションでは「共通の実データを元に、参加者が分析を競う」ことがテーマです。
我々のチームでは、スーパーの購買履歴データから、近い将来に購入額が低下して離れていく顧客を予測することを目標としました。本記事では、我々の取った解析アプローチと解析結果の概要を紹介します。
by Hirakawa 2015/06/24
機械学習を用いた解析アプローチ
ISPでは、機械学習を用いたデータ解析の研究を行っており、今回のコンペティションでも機械学習を用いた解析を研究テーマとしました。
機械学習では、タスクを実行するために必要な学習を、データから自動的に行います。ここでいうタスクとは、顧客のクラスタリング、顧客行動の予測、問題顧客の判別など、データを使って実現したい内容のことを指します。機械学習には様々な手法が存在しますが、入力するデータの質や量、タスクの内容を元に適切な手法を選定します。
人工知能分野のサブフィールドである機械学習には、高度でアカデミックな印象があるかもしれません。しかし、アマゾンの本の推薦、メールのスパム判定、手書き文字の認識など、機械学習は研究室の中にだけ存在するのではなく、実際に様々な場面で活用されています。
機械学習の手法の中から目的に応じた適切な手法を選択し、使いこなすためには実データでの解析ノウハウの蓄積が必須であり、実際の購買データを解析し経験を得る機会としてISPは今回のコンペティションに参加しました。
問題定義と手法の選択
問題定義として前述の「タスク」と「入力」を以下としました。
- タスク
毎月一定額以上を購入している優良顧客の中から、来月の購入額が大きく落ちる顧客を予測する - 入力
3ヶ月分の商品カテゴリ別・時間帯別の購入額
入力を決めることは、どの情報が有ればタスクを解決できるかの仮説を立てることです。上記では、優良顧客の過去3ヶ月分の購買カテゴリと購買額の傾向から、その顧客の来月の購買額を予測できるという仮説を置いています。
次に学習の手法を選択しますが、今回は異なる手法での検出精度を比較するため、Random Forest, SVM, Boosting手法など複数の手法で検証を行いました。
本記事では、その中でも最も良い精度が得られたBoosting手法での結果を紹介します。Boosting手法では多数の条件(弱仮説)の中からどれが有力かを学習し、ターゲットを検出するための重み付き多数決の式を学習します。
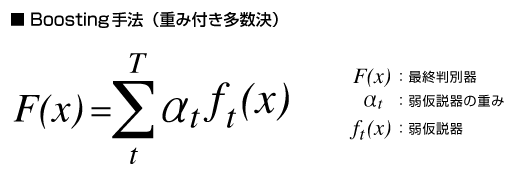
解析結果
Boosting手法を用いて得られた検出精度の計測結果を下図のグラフに示します。購入額が低下する顧客か否かは、検出閾値を設けて判定します。この閾値の基準を厳しくすると確度が高い顧客だけが選別されるため、下図横軸の誤検出率の値が低く、縦軸の未検出率が高くなります。
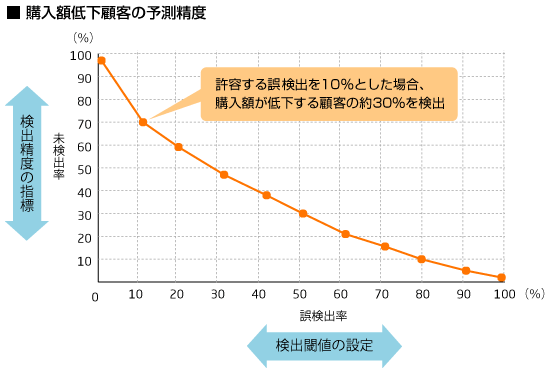
閾値を調整して誤検出を10%とした時に、来月に購入額が低下する顧客のうちの約30%を検出することができました。これだけのリスク顧客を特定できればビジネス施策を打つことも可能と思われるので、有意な成果が得られたと考えられます。
今後の展望
検出精度の向上のために、以下の追加検証が考えられます。
- 2~3年分のデータで解析
今回は提供されたデータが1年分であったため、その一部の7月から11月までの購買履歴を学習データに用いて、1月時点の顧客のステータスを予測させました。しかし、顧客の購買傾向には季節変動があるので、学習データを増やして2~3年分のデータを用いれば季節的な特徴も学習され、検出率が上がる可能性があります。 - 学習データの前処理を工夫
学習データを作る過程で今回は購入額の履歴から顧客の月単位の購入額を集計する処理を行っています。このようにデータを加工することで、より特徴が抽出しやすくなる場合もありますが、集計を行うことによって情報が失われ、精度が低下する場合もあります。学習データの作り方のバリエーションを増やし、比較検証を行うことが望まれます。