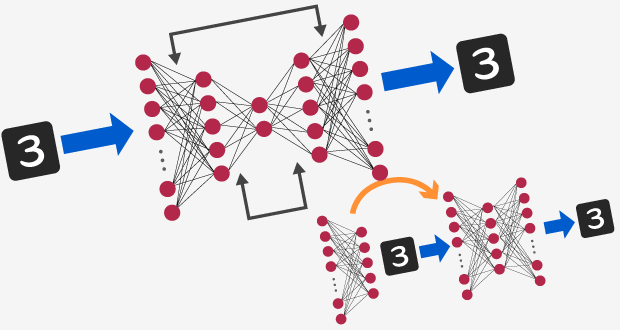
Deep Learningフレームワークの一つであるChainerを用いてStacked Auto-Encoderの処理を実装し、MNIST (手書き文字認識) のデータの分類を試してみました。
なお、本記事はNeural Network (以降NN)、Deep Learning についての基本的な知識、ChainerやPythonについての基本的な知識があることを前提としています。
(2016/03/18 追記・修正)
FunctionSet で書いていたソースコードをChainer 1.5 で追加された仕組み「Chain・Link」で書きなおしてみました。以下、通常版として公開しています。
合わせて、全体的に「Chain・Link」使った内容に修正しています。
本記事で作成したソースコードはGithub上に公開しています。
(通常版)
https://github.com/ISP-Kazuki-Nagasawa/chainer_1.6_sda_mnist_sample
(Chainer 1.5 未満版)
https://github.com/ISP-Kazuki-Nagasawa/chainer_sda_mnist_sample
by Nagasawa Kazuki 2015/12/10
実行環境
| OS | Ubuntu14.04 (LTS) |
|---|---|
| Python | 2.7 or 3.4 (旧版は 2.7 のみ) |
| Chainer | 1.6、1.7 (旧版は 1.4.1 で確認) |
手法について
本記事で使用している手法「Stacked Auto-Encoder」について、単純な例である「Auto-Encoder」とStacked Auto-Encoderの初期化方法である「Layer-Wise Pretraining」を紹介します。
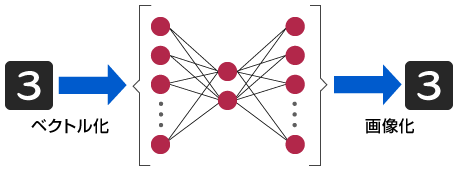
Auto-Encoder
NNの一手法で、以下の特徴を持っています。
- 入力層、隠れ層、出力層の3層構造。
- 入力層と出力層のニューロン数は同じ、上下対称のNN。
- 教師データとして、入力データそのものを用いる。
入力データが一度圧縮され、元に戻るような構造をしているので、一種の次元圧縮器として利用されます。
Stacked Auto-Encoder
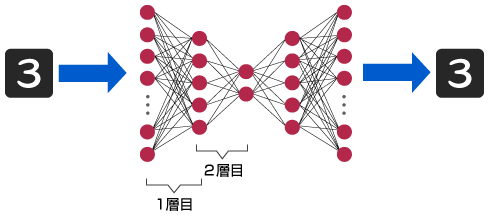
名前の通り、Auto-Encoderを積み上げて多層化したものです。
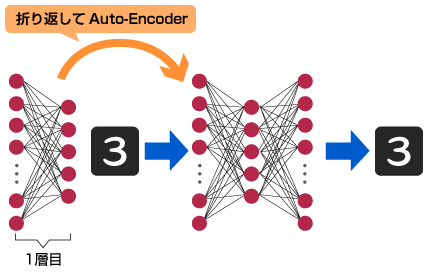
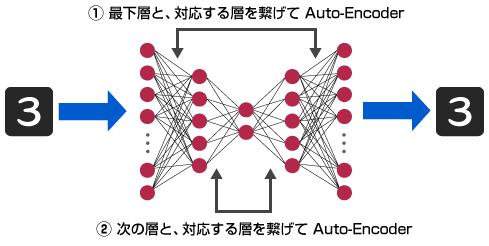
ただし、そのまま多層化して扱うだけでは、ニューロン数が多すぎるためNNの学習がうまく行きません。そこで、下層部から順次学習を行う「Layer-Wise Pretraining」、その後全体の学習を行う「Finetuning」により効率よくNNを最適化します。
ここでは、Layer-Wise Pretrainingについて、以下に示します。
NN全体例
(1) 1層目だけ抜き出し、Auto-EncoderとしてNNを最適化
(2) 2層目だけ抜き出し、Auto-EncoderとしてNNを最適化
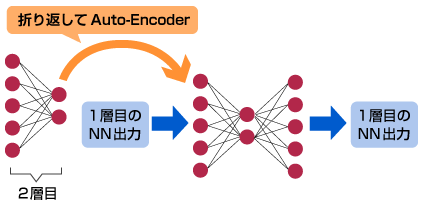
(3) 最上層まで繰り返す
Chainer によるStacked Auto-Encoder実装
Chainerを用いてStacked Auto-Encoderを実装してみました。公開しているサンプルソースコードのlibs/stacked_auto_encoder.pyがそれに当たります。
特長としては以下を持っています。
- NNの層数は可変。理論上何層でも設定可能。(マシンリソースによる限度はあります。)
- ミニバッチ法を採用。アプリケーション側でバッチ数を指定して学習を進めることができる。
- ChainerのGPU処理も取り入れている。設定によりGPUの使用有無を指定可能。サンプルソースコードでは、settings.pyで上記の設定を行うことができます。
Layer-Wise Pretrainingの部分については、実装の簡略化のため『下層から順次Auto-Encoderして最適化』するのではなく、『NNの “外側” から順次Auto-Encoderして最適化』しています。この方法でも、後に示すように効果は上げています。
サンプルソースコード
作成したStacked Auto-Encoderを用いて、MNIST (手書き文字認識) の画像データセット (28 × 28 ピクセル) を学習させてみました。
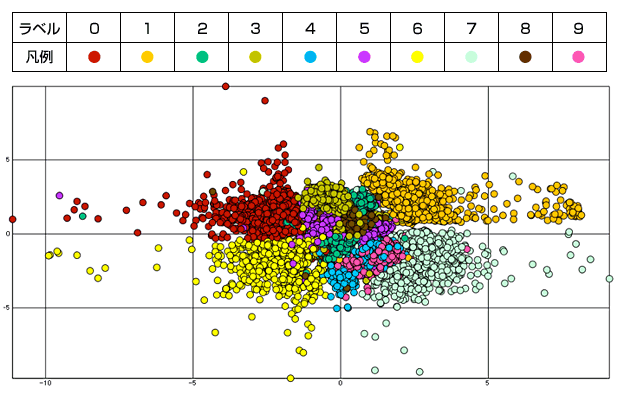
NNの層は [(28 × 28 = ) 784, 1000, 500, 250, 2] と設定し、ニューロン数2の層の値を(x, y) 座標として座標空間上に布置しました。
各層Pretrainingを500 epoch、Fine tuningを200 epoch 実施した結果が下記です。
MNISTのラベル0~9で色分けして表示した結果、ある程度綺麗に分類されているのが確認できます。
なお、MNISTのデータダウンロードと読み込みについては、Chainer のサンプルコードを利用しています。
https://github.com/pfnet/chainer/blob/master/examples/mnist/data.py
作成したソースコードはGithub上に公開しています。
https://github.com/ISP-Kazuki-Nagasawa/chainer_1.6_sda_mnist_sample
(おまけ) ソースコードで工夫した所
今回、ChainerでStacked Auto-Encoderを実装するにあたり、NNの層数を動的に扱う必要がありました。動的に設定することができれば、簡単に実装モジュールの外側でNNの構成を変えることができるからです。
Chainerでは通常、NNのクラスのコンストラクタで変数として層を定義してしまうため、この呼び方では動的な設定が叶いません。
しかし、chainer.Chainクラスのメソッド「addlink」「__getitem__」を使うことにより、この問題を解決しました。
通常
class ChainModel(chainer.Chain) :
def __init__(self, train = True) :
super(ChainModel, self).__init__(
l1 = L.Linear( 784, 1000),
l2 = L.Linear(1000, 784),
# ... (略)
)
def __call__(self, x) :
h1 = F.sigmoid(self.l1(x))
h2 = F.sigmoid(self.l2(h1))
# ... (略)
「addlink」「__getitem__」 使用版
class ChainModel(chainer.Chain) :
def __init__(self, layer_sizes, train = True) :
super(ChainModel, self).__init__()
self.size = len(layer_sizes) - 1
for idx in range(self.size) :
self.add_link("l{0}".format(idx + 1),
L.Linear(layer_sizes[idx], layer_sizes[idx + 1]))
def __call__(self, x) :
h = x
for idx in range(self.size) :
h = F.sigmoid(self.__getitem__("l{0}".format(idx + 1))(h))
# ... (略)
まとめ
Chainer で Stacked Auto-Encoderを実装し、MNISTのデータが分類できることを実験してみました。
私はいままで、Deep Learning フレームワークはCaffeを用いて課題に取り組んでいました。Caffeと比べるとChainerはプログラミングで書く部分が大半を占めていて、Caffeよりは慣れるまでに時間はかかりました。しかし、NNの設計については、Caffeでprototxtを記述するよりもソースコードで書く方が良く理解できました。(プログラミングに慣れていたのもありますが。)
今後は、このソースコードに更に改良を加えて、色々と実験を行っていきたいと思います。