Deep Learningを使うには、問題設定に合致するデータが大量に必要になります。画像データであれば、実際に現地での撮影し、様々な状況を想定しながら地道に少しずつデータを蓄積させる必要があり、簡単ではありません。更に、それらのデータにラベルを付けて、分類して・・・となると多大な労力がかかります。
今回は、Deep Learningで使う学習用データを、ISPが持つ高品位合成技術を用いて作成し、Deep Learningの学習で良い結果を示せたので紹介します。
by Kondo Takanori 2016/1/20
ISPの取り組み~つくばチャレンジ~
ISPでは、近年培ったDeep Learningのノウハウをロボティクスに応用したいと考え、その一環として宇都宮大学の尾崎研究室のグループと共同研究で「つくばチャレンジ」に参加しました。
自律走行ロボットがこなすべき課題の一つに、指定された区域の中で、指定された人や物を探しだし見つけるというものがあります。
Deep Learningを用いて物体検出
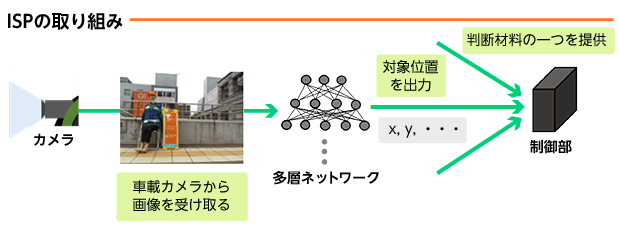
ISPでは、自律走行ロボットに搭載されたカメラから得られる画像を用いて、Deep Learningによって指定対象を検出する取り組みをしました。今回は検索対象の人物の隣に必ず置いてある看板を検出することを目指しました。
検出結果はロボットの制御部で他の判断材料とともに活用され、ロボットの自律走行に影響します。そのため、精度の高い検出結果が必要であり、学習用データも良質な大量のデータが必要になります。
データの収集
Deep Learningでの学習を成功させるためには、十分な量の良質なデータを準備する必要があります。
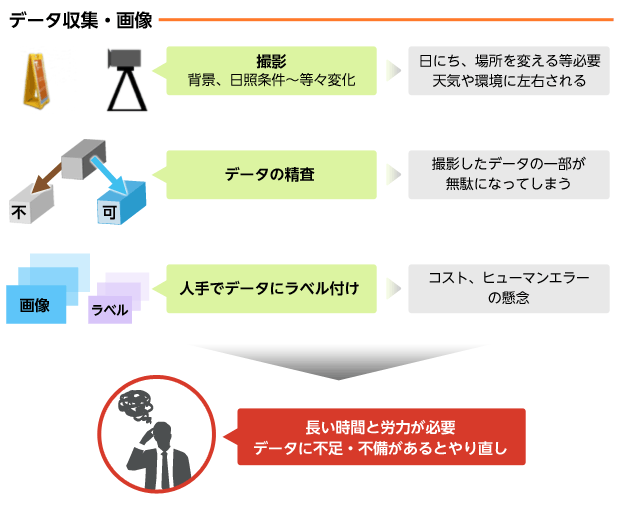
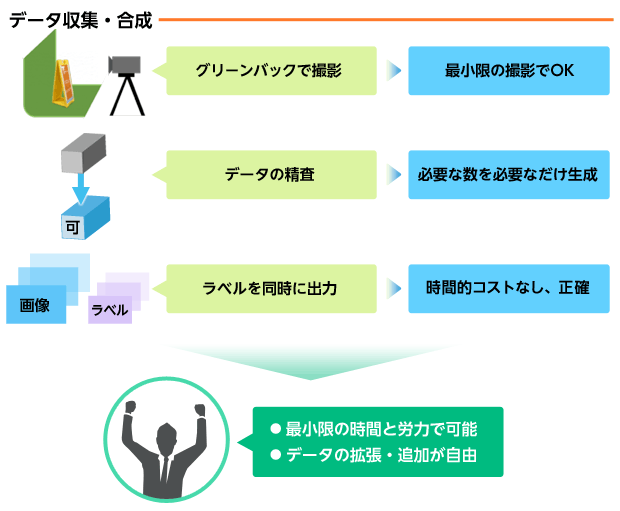
事前に十分なデータがない場合、一般的には、図のように大量に撮影し、精査し、一つ一つに正解ラベルを付与して学習用データを収集します。
例えばつくばチャレンジでは、収集作業を行う際にいくつもの問題がありました。
- 実際のつくばチャレンジのような町中に検出対象がある状態で撮影できる機会が限られている
- 撮影してデータが準備できても、検出対象の見え方に偏りがあるため、学習に適さない
このような場合はこの例に限らず、物体検出に取り組む際によくあると考えられます。そこで、上記の問題を解決でき、大変な労力を要するデータ収集を効率よく進める方法として、背景合成によるデータ生成に取り組みました。
背景合成データ生成
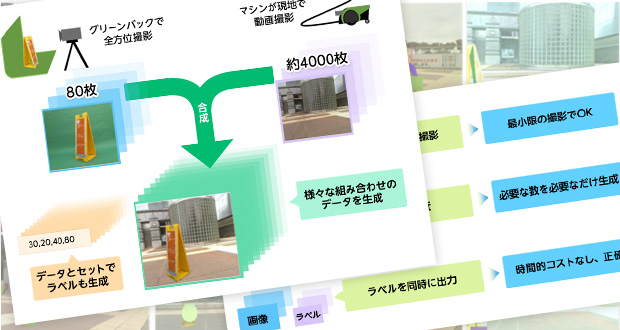
ISPがもつクロマキー合成技術を使い、看板を撮影し、つくばチャレンジコース背景を合成することでデータを生成しました。
看板は約18度ずつ回転させ、前後対称なので片側180度分を2往復で40枚、撮影高さの違いを入れて合計80枚撮影しました。背景画像はつくばの対象探索エリアを実際にロボットが走り撮影した動画データから4000枚の静止画を得ることが出来ました。
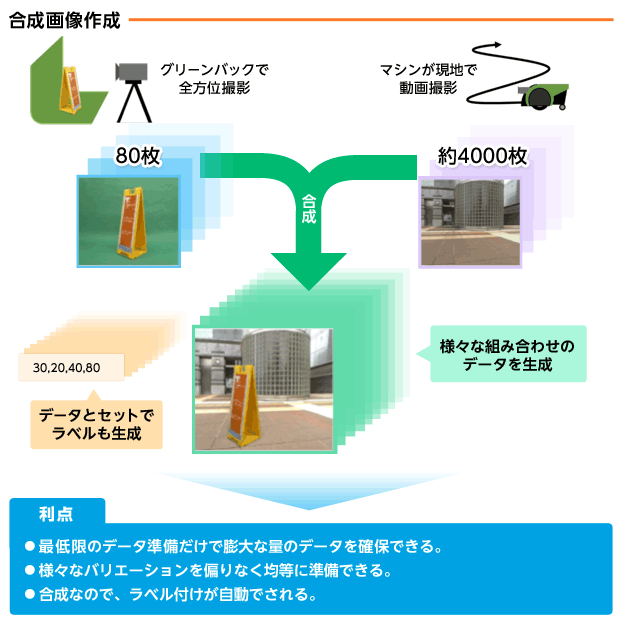
合成した画像に輝度変化、拡大・縮小、などの画像加工を施すことで少ない看板データでもバリエーションに富んだデータを生成できます。実用上ではほぼ無限に異なるデータを用意できます。

データ拡張には、よく使われる微小回転や拡大縮小、色合いの変化などに加え、今回は対象の前を人が通過する、カメラと対象の間に障害物があるなどの状況を想定し、新たな取り組みとして簡単な図形を上に合成することで隠れのあるデータも生成しました。
背景合成によるデータ生成方法であれば、実際に様々な状況を用意して多くの時間と人数をかけて撮影やデータの分類を行う作業がなくなり、Deep Learningを用いた学習までのハードルが大幅に下がります。
学習へ
こうして得られた合成データを用いて、画像のどの位置に対象がいるかを、2通りの方法で取り組みました。
一つは、入力される画像を領域分割し、どの領域に物体が属するかを学習します(領域判別)。その際、データを対象が属する領域ごとに分類する必要がありますが、データ生成で一緒に作られたラベルをもとに画像のどの領域に看板があるか数値的に分かるので、振り分けを正確かつ簡単に行えました。
もう一つは、入力される画像のどの位置にどれくらいの大きさの対象があるかを数値で出力させます(対象検出)。こちらはラベルとして看板の位置・大きさを与えることで学習を行います。
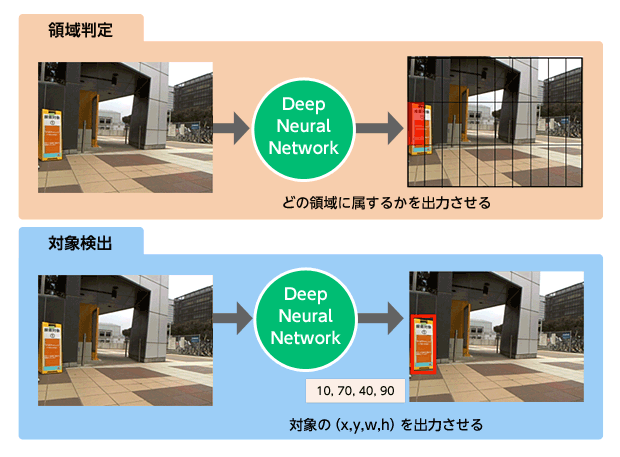
どちらの方法でも、画像中のどの位置に対象があるかを高い精度で検出できました。
今後に向けて
今回、実データの収集困難性を解消する方法として、合成画像に取り組んでみました。結果としては、合成画像でも十分に学習が進み、性能が出せました。今回は見え方によっての形状がある程度固定されており、また他の物体と区別しやすい対象でした。今後はより一般的な物体で、例えば人物に同様のアプローチを試みた場合などに取り組んでいきます。
データの拡張に一般的によく用いられる色味の変化、拡大縮小などの他に新たな加工として簡単な図形で意図的に隠れさせる処理を実験的に行いました。今後は現地のオブジェクトや、通行人をかぶせる、や看板の影や建物の影が看板に部分的にかかる様など、より現実に近い隠れデータの生成に取り組みたいと思います。
私自身、学習用データを実際に撮影して、その苦労を経験してきましたが、データを合成により生成してみて拍子抜けするほど簡単に集めることができました。なにより撮影の計画や、集めたデータの分類などの気の遠くなるような作業をしなくてもよいことは、労力的にもスピード的にも大きなアドバンテージだと考えます。