第4回Deep Learningセミナーで展示した、Jetson Tegra K1(TK1) + Deep Learning + cuDNN v2(version2)による手形状認識について紹介します。Deep Learningによる推論部分をcuDNN version2を用いて独自実装することで、Tegra TK1でも5ms程度で認識処理を完了させることができました。
by wazalabo-editor 2015/06/23
Jetson Tegra K1
Tegra K1は世界初CUDAを搭載したSoC(System on Chip)で、Jetson Tegra K1はその評価ボードになります。
ハードウェアスペックは以下の様になっており、CUDA, OpenGL 4.4, Tegra Accelerated OpenCVが動作します。
| GPU | 192 CUDA コア搭載 NVIDIA Kepler GPU |
|---|---|
| CPU | NVIDIA 4-Plus-1™ クアッドコアARM® Cortex-A15 CPUPU |
| Memory | 2GB DDR2 |
cuDNN
cuDNNはNVIDIAが提供しているDeep Neural Networksのライブラリで、Deep Learningで使われるConvolutionや非活性関数などのルーチンが実装されています。
CaffeやTheanoといったDeep Learningのフレームワークと組み合わせることができ、これらフレームワークのデフォルトのGPU実装よりも高速に動作します。
現状の最新版はversion2であり、Tegra K1で実行可能なライブラリも公開されています。
NVIDIA® cuDNN – GPU Accelerated Deep Learning
手形状認識
手形状認識は以下の画像の様に指の本数を認識するエンジンでDeep Learningを用いて試作してみました。
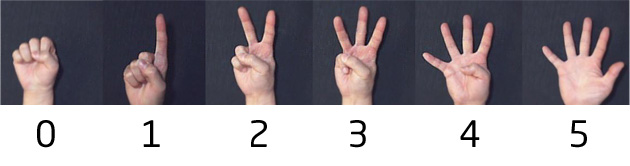
システム構成
システム構成は以下になります。USB WebCameraによって撮影した画像を手形状認識エンジンに渡し、結果を画面に出力します。今回Deep Learningの学習は別マシンで実施しており、そこで得られた重みを使用しています。

動作時の動画は以下のものです。画面中央にある機器がJetson TK1になります。
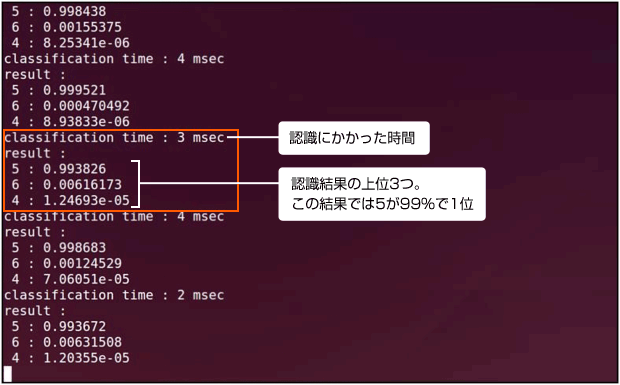
実行中、ターミナルには1回の認識処理にかかった時間とその結果を出力しています。
独自実装による高速化
当初このエンジンは、Deep LearningフレームワークであるCaffeを利用して識別を行っていました。CaffeはLinuxで動作するためJetson TK1への移植は容易だったのですが、認識処理に時間がかかっていました(20-30ms)。Caffeが対応しているcuDNNがversion1だったこともあり、認識処理をcuDNN version2にしようと考えました。さらに重みの読み込みやネットワークの定義などの周辺処理を独自にC言語で実装しCaffeをしようしないことにしました。実装し、最適化を行ったところ、認識処理の時間を5msまで高速化できました。また画面の出力にはJetson開発キットのOpenCVを使用していましたが、表示が低速だったため、こちらにも工夫を加え取り込みから出力までを含めて33msの処理時間(30fps)を実現しました。
手法毎の認識処理時間比較
| 手法 | 認識処理時間 |
|---|---|
| caffe(cuDNNv1) + python (*1) | 23ms – 25ms |
| caffe(cuDNNv1) + c | 20ms – 30ms |
| cuDNNv2 + c | 5ms |
(*1) 測定時、caffeはcuDNNv1のみに対応
結論
Deep Learningによる手形状認識をJetson TK1上で動作させることを試みました。Deep Learningの周辺部分をC言語で独自実装しcuDNN v2を使用することにより認識処理時間を5msとすることができました。またJetson TK1上のOpenCVに工夫を加える事により、画像の取り込みから出力をまでを含めても33ms(30fps)で実行できることが確認できました。