
ISPでは以前より2D Convolution Neural Networkを用いたハンドジェスチャ認識を行ってきましたが、この度3D Convolutionを使ったハンドジェスチャ認識にチャレンジしてみました。さらに、MSRAのチームが提唱するResidual Networkを取り込み、従来の1/10の学習回数で10%以上性能の良いモデルを学習させることができました。
本記事ではこの手法について説明します。
なお、ハンドジェスチャ認識については別記事を参照下さい。
by Okumura Yoshikazu 2016/01/15
3D Convolutional
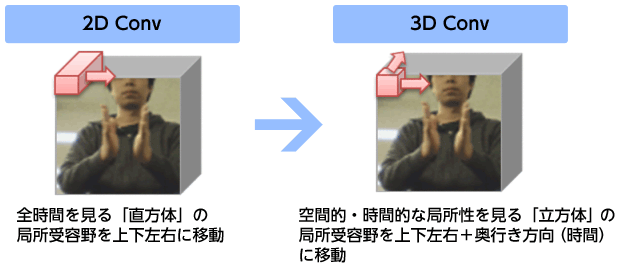
CNN(Convolutional Neural Network)ではデータの局所性を用いて効果的な学習を行います。例えば、静止画に対するConvolutionでは、3×3ピクセルや11×11ピクセル等の小領域に対する処理が基本にあり、注目する領域をずらしながら画像全体を処理します。CNNは視神経の構造をモデル化している為、神経学の用語を流用して「局所受容野」と呼ぶことがあります。
一方、ハンドジェスチャの様な動画では、データは縦・横の他に時間方向の奥行きを持つデータと捉える事ができます。3D Convolutionはまさにその様な局所受容野を持ち、「幅・高さ・時間」の3次元の小領域に対する処理を基本とします。
以前のハンドジェスチャ認識では、空間的には局所的ですが時間方向は全時間を見る「3D Convolution風」のものでしたが、今回はちゃんと時間方向も局所的に見るカッコ無しの3D Convolutionを行いました。
Residual Network
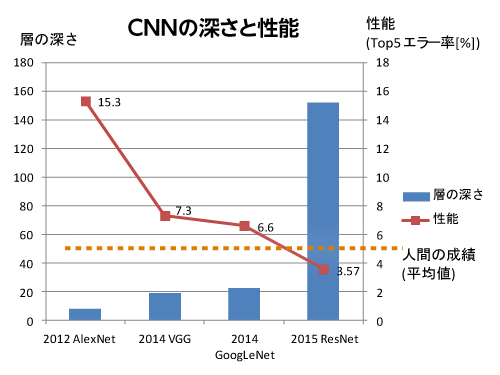
Residual Networkは2015年のILSVRCやMSCOCOなどのコンテストで1位を取った手法です。非常にネットワークを深くしても良好な性能が得られるのが特徴で、1位を取ったネットワークはなんと152層(!)もあります。
代表的なネットワークと比較するとこの様な感じになります。青棒が深さを表します。圧倒的な深さですね。赤線が性能を表します。人間の成績の目安である5.1%を上回る、3.57%を達成しています。なお、この数字は不正解率なので、低いほど成績が良いことを意味します。
3DConvolution + Residual Network結果
実験に用いたデータセットはハンドジェスチャ認識紹介と同じですが、記事に比べて画像サイズが小さい60×60ピクセルを用いました。フレーム切り出しは記事と同じ12フレームです。
性能
AlexNetベースや独自に色々工夫したネットワークでは80%程度が限界値だったのですが、93%を達成することができました。
収束の早さ
Deep Learningでは繰り返し法を用いて学習を行います。繰り返し回数はAlexNetベースの手法では1万~4万回程度必要だったのですが、本手法では数千回程度だったので、1/10位の学習回数で収束しました。
ハイパーパラメータの調整
すいません、やってません。とりあえず動作確認用の値で動かしてみたら上記の性能がでてしまいました。恐るべし…。
まとめ
最新手法であるResidual Networkと3D Convolutionを組み合わせてハンドジェスチャー認識をやってたところ、これまでの性能を10%以上上回ることができました。
一般的には時系列データはRNN特にLSTMを使うことが多く、特に動画にはCNNを特徴抽出器としてLSTMと組み合わせることが多いかと思います。個人的には動画もConvolutionで扱ってend-to-endで学習できると面白そうだなと感じています。
今後はハイパーパラメータの追いこみや、他のデータセットで試してみる等研究を進めて行きたいと思います。