第一回の記事でご紹介したハンドジェスチャ認識について具体的にどのように学習を実施していったかを解説します。
by wazalabo-editor 2016/01/16
認識エンジン開発
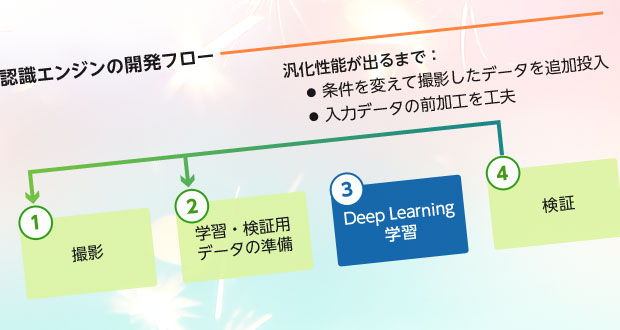
学習・検証用画像の撮影から、Deep Learningによる学習と検証まで、下図①~④のサイクルを繰り返し行い、認識能力を段階的に強化しました。ハンドサイン認識での経験を活かし、1ヶ月の短期間で、簡単のデモを室内で行えるレベルまで認識精度を向上させることができました。

① 撮影
当社社員約20名に被写体として協力してもらい、ジェスチャの動画を撮影しました。学習後に室内である程度の認識ができるようになることを目指し、照明条件や撮影場所を変えて様々な環境で撮影を行いました。
② 学習・検証用データの準備
撮影した動画から順に一秒分のフレームを切り出し、ジェスチャ毎に約1万個のデータを作成しました。これらは被写体が被らないように学習用と検証用データに分けます。動画からのフレーム切り出しは12fpsと24fpsの二つのレートを試しました。しかし、特に学習結果に有意な差がなかったため、最終的なデモで認識の処理負荷が少なくなるように切り出しレート12fpsを採用しました。
学習用データの画像には、画像内の手の位置や明るさなどを変更するデータ拡張を行います。これにより、よりロバストな認識器の学習が期待されます。
最後に画像データをDeep Learningに入力するデータ形式に変換します。今回は生のRGB値を入力とするケースの他に二つのデータ形式で学習を行いました。試したデータ形式と学習結果は後述の「④検証」の表に記述します。
③ Deep Learning学習
Deep Learningのネットワークには通称AlexNetと呼ばれる、画像物体認識で実績のあるネットワークを採用しています。その構造は入力と出力部の違いを除き、下記記事でご紹介したネットワークと同じです。
Deep Learningによるハンドサイン画像認識デモ 解説 (第三回)
学習にはGPUにGeForce GTX 980 Tiを搭載したデスクトップPCを用いました。12フレームずつのデータを約4万個投入して、1epoch約4時間の学習時間となりました。
④ 検証
「② 学習・検証用データの準備」で述べましたが、学習は三つのデータ形式で試しました。試したデータ形式とその学習結果を下表に示します。
表1 Deep Learning学習データのデータ形式とその学習結果比較
| No. | データ形式 | 検証用データに対するAccuracy |
|---|---|---|
| 1 | 生のRGB値 | 0.905 |
| 2 | RGB(肌色部分以外には半透明のマスクを適用) | 0.922 |
| 3 | グレースケール化 | 0.125 |
データ形式2は、ジェスチャの特徴が表れている画像内の肌色の部分以外を半透明にすることにより、ジェスチャの特徴をより強調することを目的として作成しました。この工夫により、生のRGB画像を用いるよりも高いAccuracyを得ることができました。
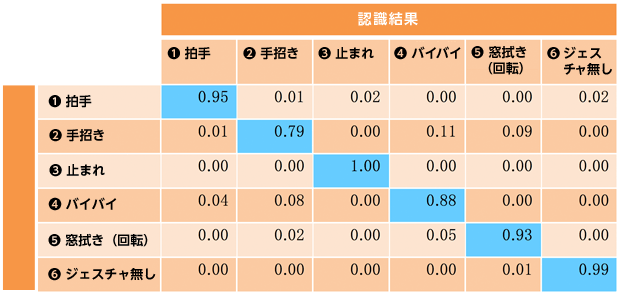
データ形式2で認識した結果のConfusion Matrixを下表に示します。水色のセルがジェスチャ毎の正答率を示します。手招きの認識をもっとも苦手としていることが分かります。手招き以外の手が上下左右に動くジェスチャや手が静止状態の「③ 止まれ」については比較的良好な認識率となっています。
表2 データ形式2 学習結果のConfusion Matrix
最後にデータ形式3で色成分を排除してグレースケールで学習を行いました。NN (=ニューラルネットワーク) にジェスチャを色ではなくて形状で学習させる試みでしたが残念ながら低いAccuracyとなり、色情報が重要な要素になっていることが伺えます。
最も成績が良かったデータ形式2で学習した認識器を実際に室内で動かしたところ、大体ジェスチャの判別が行うことができました。短期間での実験でしたが、ジェスチャをある程度認識できる認識エンジンの開発に成功しました。
今後のテーマ
Deep Learningによるジェスチャ認識をテーマに、今回は比較的単純な実験から始めました。より実用的な技術習得を目標に私達が考えている今後のテーマを二つご紹介します。
① 時間軸方向の畳み込み
今回はDeep LearningのネットワークにAlexNetを利用しましたが、AlexNetでは畳み込み層での畳み込み処理がRGBのチャンネル毎に適用されるので、時間軸方向の前後が考慮されていない学習になっていると考えられます。その場合、窓ふきジェスチャ(前記事参照)で手の動きが時計周りなのかその逆なのかといった学習ができません。
時間軸も考慮したより正確な認識ができるよう、私達は時間軸方向の畳み込みを入れた学習実験を行いたいと考えています。
② 認識エンジンの軽量化
AlexNetは一千カテゴリもの画像を判別する、より高度な問題解決のために編み出されたネットワークです。今回はジェスチャのカテゴリも六個と少ないため、単純化したネットワークでも同様の学習が可能と思われます。また、入力画像についてもAlexNetと同じ256×256ピクセルより小さな画像でも認識できる可能性も考えられ、認識エンジンを軽量化してよりライトなスペックのPCやJetson TK1のような組み込みボードで動作させることが可能かもしれません。