by Watase Satoshi 2016/6/2
はじめに
Amazon Web Service(以降AWS)のIaaSであるEC2のGPUインスタンスを用いてDeep learningフレームワークCaffeを動かしてみます。ただ動かすだけでは味気ないので今までオンプレミスサーバやJetsonで動作させてきた実績のあるハンドサイン画像認識器の移植を試みましょう。ハンドサイン画像認識に関しての詳細は以下の技ラボ記事を参照してください。
Deep Learningによるハンドサイン画像認識デモ 解説 (第一回)
Deep Learningによるハンドサイン画像認識デモ 解説 (第二回)
Deep Learningによるハンドサイン画像認識デモ 解説 (第三回)
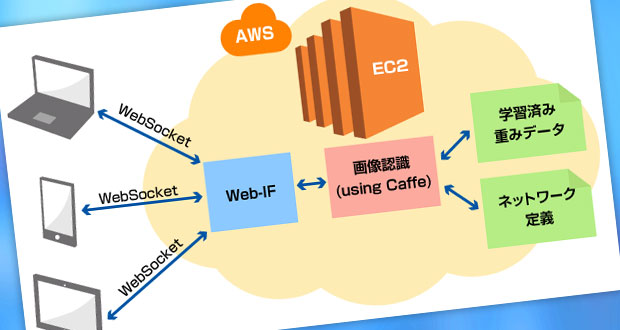
今回動作させた仕組みの概略は以下の通りです。
「クラウドでハンドサイン認識サーバを立ててみた」は「環境構築編」と「アプリ評価編」の全2回でお送りします。今回はアプリ評価の話。
前回の環境構築編では、スポットインスタンスを立ち上げ、Cuda7.5+cuDNNv4+Caffe+Python2.7を動作させる環境を構築しました。今回はその環境にハンドサイン認識サーバを動作させ、そこにPCやモバイル端末のWebブラウザからサーバにアクセスすることで手元のハンドサインを認識させます。
端末側Webアプリでは、HTML5のMediaStream APIを用いてWebブラウザ上からWebカメラやモバイル端末のカメラ画像をリアルタイムで取得し、取得した画像をWebSocket経由でサーバに画像をストリーミング転送します。 サーバアプリでは転送された画像を認識し、認識結果をWebSocketで端末に返送します。 返送された認識結果はPCやモバイル端末の画面にリアルタイムグラフ表示されます。
技術要素
- Deep Learning
- AWS
- MediaStream API
- Itamae
- WebSocket
画像認識アプリ
サーバ側で動作させるハンドサイン認識アプリケーションはPython2.7で主にWebフレームワークflaskと WebSocket通信ライブラリgevent-websocketを用いて実装しました。今回は8080ポートでWebSocketを待ち受けます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from geventwebsocket.handler import WebSocketHandler
from gevent.pywsgi import WSGIServer
from flask import Flask, request, render_template
from werkzeug.exceptions import abort
import cv2
import numpy as np
import sys
import base64
from hand_sign_classification import Classifier
import json
import time
app = Flask(__name__)
# 独自学習させた判別器
classifier = Classifier()
class NpEncoder(json.JSONEncoder):
""" Numpyオブジェクトを含むオブジェクトのJsonエンコーダ """
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(NpEncoder, self).default(obj)
class Timer(object):
"""処理時間計測ユーティリティクラス"""
def __init__(self, verbose=False):
self.verbose = verbose
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
self.end = time.time()
self.secs = self.end - self.start
self.msecs = self.secs * 1000 # millisecs
if self.verbose:
print 'elapsed time: %f ms' % self.msecs
@app.route('/sock')
def sock():
# WebSocket オブジェクトの取得
ws = request.environ['wsgi.websocket']
if not ws:
print("abort")
abort(400)
while True:
try:
# WebSocketデータの受信
message = ws.receive()
messagedata = json.loads(message)
# Base64デコード&cvimageに変換
image_data = from_base64(messagedata["data"])
uuid = messagedata["uuid"]
# クラス判別と時間計測
with Timer() as t:
classify_results = classifier.classify(image_data)
print(classify_results)
result = { "uuid": uuid, "class": classify_results, "calc_time":t.msecs }
except Exception as e:
print 'error:' + e.message
ws.send(json.dumps(result, cls=NpEncoder))
def from_base64(b64msg):
"""Base64文字列をcv2イメージにデコード"""
img = base64.b64decode(b64msg.replace("data:image/png;base64,",""))
npimg = np.fromstring(img, dtype=np.uint8)
image_data = cv2.imdecode(npimg, 1)
return image_data
if __name__ == '__main__':
# WebSocketHandler が
http_server = WSGIServer(('0.0.0.0', 8080), app, handler_class=WebSocketHandler)
http_server.serve_forever()
端末側で動作するHTML5ページでは、MediaStream APIを用いてカメラ画像を取得します。ブラウザの対応状況によると、2016/5/25現在、Edge, Chrome, Firefox, Opera, Android5.0 WebView, Opera(Android), Chrome(Android), Firefox(Android)などがこのAPIをサポートしています。
APIで取得した画像を40×40ピクセルに縮小した上で500msごとにWebSocket送信する部分は以下のよう20行程度で実装できてしまいます。便利ですね。
// カメラ画像取得部。webkit-/moz-/ms-など各ブラウザにより呼び出し方法が違うため、処理をWrapする
navigator.getUserMedia = (navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia);
if (navigator.getUserMedia) {
navigator.getUserMedia(
// ビデオ画像のみを取得する
{ video: true, audio: false },
function (localMediaStream) {
// ビデオストリームの設定
video.src = window.URL.createObjectURL(localMediaStream);
// ビデオを再生
video.play();
},
function (err) {
console.log("error: " + err);
}
);
// 送信用データを書き出すためのCanvasを生成
// このCanvas自体はdisplay:noneでユーザからは不可視
var sendCanvas = document.getElementById('sendimage');
var sendCanvasContext = sendCanvas.getContext('2d');
// 500msごとにデータ送信
timer = setInterval(
function () {
// 送信ごとにレスポンス時間を計測するため、UUIDを生成
var uuid = getUniqueStr();
// 480x480のキャプチャ画像を認識器が入力とする40x40まで縮小
sendCanvasContext.drawImage(video, 0, 0, 480, 480, 0, 0, 40, 40);
// 画像データをBase64エンコード
var data = sendCanvas.toDataURL();
// データをjson形式で送信
var sendObj = { uuid: uuid, data: data}
ws.send(JSON.stringify(sendObj));
// レスポンス時に比較するため、送信時刻を記録
sendData[uuid] = performance.now();
}, 500);
}
else {
console.log("getUserMedia not supported");
}
アプリ動作の様子
アプリが動作している様子。カメラから取得した画像と画像認識の結果を画面上部、サーバ側画像認識器の処理時間とそれ以外の通信に要した時間を画面下部に表示します。 この動画ではUS East(N.Virginia)リージョンでインスタンスを立ち上げているため、通信時間で往復250msほどかかっていますが、認識処理時間の40msと合わせても遅延はコンスタントに0.5秒以内に収まっています。
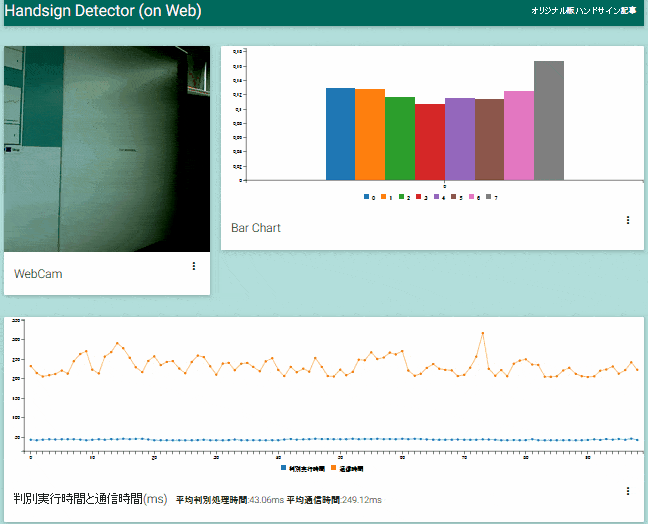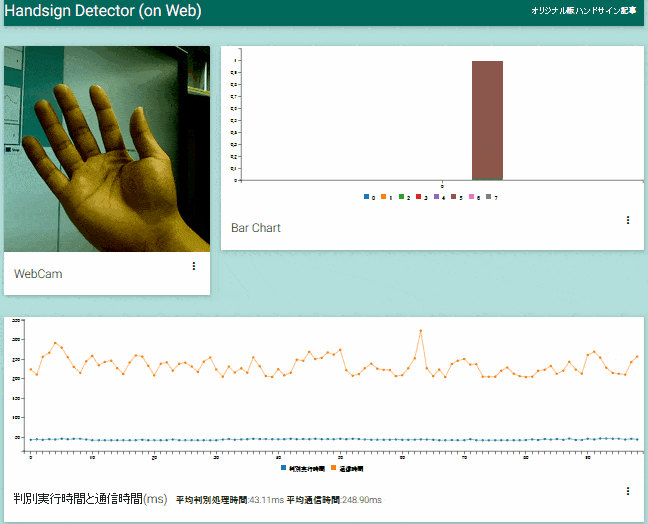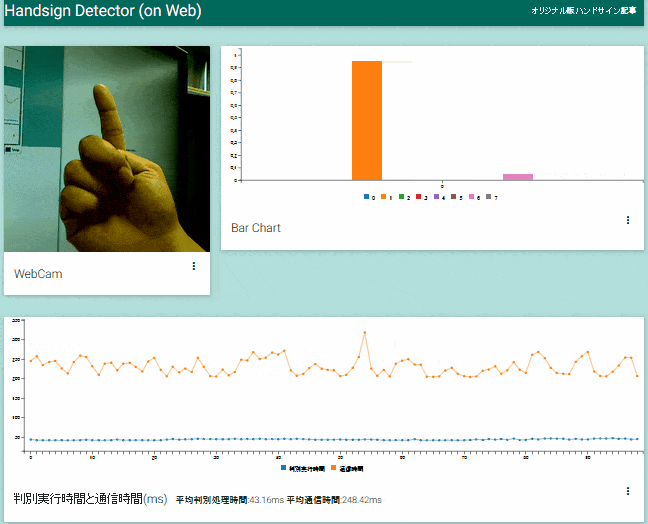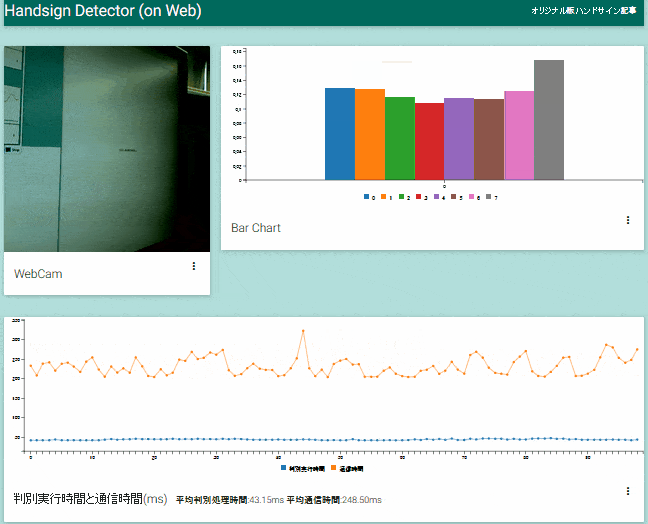
「クラウド環境は遅い?」
せっかく時間計測機能を作ったので何種類かの環境で評価してみました。
| 環境 | 詳細 |
|---|---|
| (a) g2.2xlarge(N.Virginia) | N.VirginiaリージョンでのEC2インスタンス |
| (b) g2.2xlarge(Tokyo) | TokyoリージョンでのEC2インスタンス |
| (c) 社内GPU搭載実機 | 社内にある実機(Core i7-4790/MEM32GB/GTX 970) |
3つの環境はすべて同じソフトウェア環境で評価しています。厳密な計測ではありませんが1分程度動作させた時の平均値は以下のグラフのようになりました。
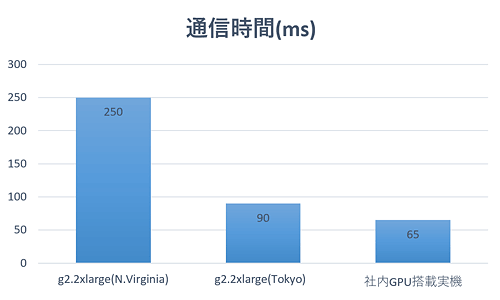
通信時間に関しては、当然ながら、米国リージョンでは遅延が発生します。これは物理的にどうしようもないですね。 東京リージョンは社内環境より30msほど遅延する程度で、体感としてはほぼ変わりません。
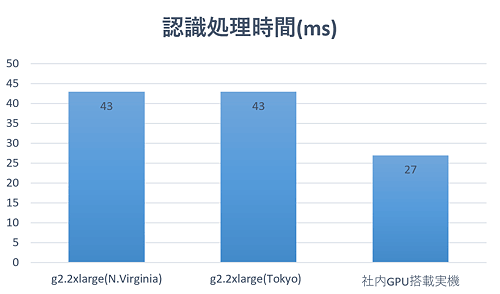
画像認識処理時間では、おそらくはGPUの性能の違いでくっきりと性能差が計測できています。(a)と(b)のg2.2xlargeインスタンスではGRID K520を、 (c)の社内実機はGeforce GTX970をそれぞれ搭載しています。CUDAコア数では1536個と1664個とそれほど大きな違いはありませんが、ベンチマークサイト (videocardbenchmark.netなど)を参照すると、やはり後発のGTX970の方が2倍近い性能を示しているように、 性能差はあるようです。ただ、これに関しても今回試作したアプリでははっきり体感できるほどの違いは感じられませんでした。
まとめ
AWS上でハンドサイン認識サーバを構築し、身近な端末で簡単に画像認識アプリを動作させることに挑戦しました。 認識器の実行環境としてのAWSは、カジュアルに”使い捨て”できるメリットを考えると、実用に足るものだと感じます。また、アプリケーションをクラウド化することにより、認識環境の物理制約がほとんどなくなることも大きなメリットです。なにしろ、インターネットに接続できる、カメラを持ったWeb端末さえあればいつでも認識器を利用できるようになるのです。これは非常に強力な利点で、認識器を広く利用したい場合に有効な手段でしょう。
コストの面でざっくりと試算してみます。20万円のエントリーレベルのGPUマシンを購入して24時間稼働させた場合は 初期費用の他に電気代が毎日180円ほどかかります(300W稼働の想定)。一方、g2.2xlargeオンデマンドインスタンスを毎日8時間稼働させた場合は 日本円にしておよそ580円の利用料金が発生します。この2つの単純なモデルで日数を経過させていくと・・
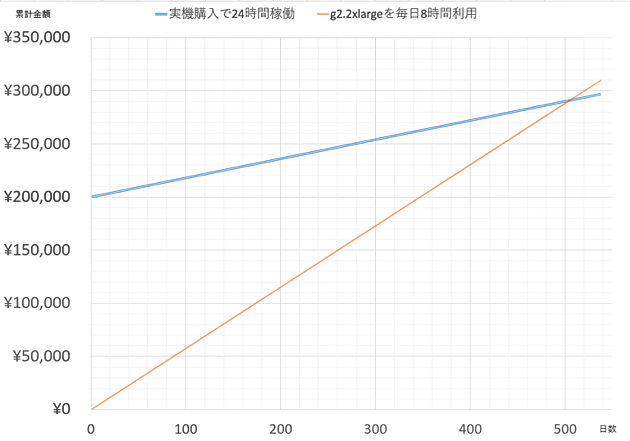
上記のように、500日程度経過して初めて実機のコストをAWSのコストが上回ります。 もちろん、今回の記事で比較した通り、ふたつは性能が違いますし、他の要因もあり単純化できるものではありませんが、 「コストがかかるから」という理由でAWSを避けるものではなさそうです。
今後も引き続き、クラウド環境の評価を続けていきます。