「ビッグデータEXPO東京 2015春」に展示しました「Deep Learningを利用したハンドサイン画像認識のデモ」について、全三回に分けて解説します。
今回は第三回、最終回です。デモアプリケーションの核となっている、ハンドサイン画像の学習について解説します。
by NagasawaKazuki 2015/05/11
- Deep Learningによるハンドサイン画像認識デモ 解説 (第一回)
- Deep Learningによるハンドサイン画像認識デモ 解説 (第二回)
- Deep Learningによるハンドサイン画像認識デモ 解説 (第三回)
はじめに
ISPは、2015年3月12日(木)、13日(金)にザ・プリンスパークタワー東京で開催された「ビッグデータEXPO 東京」に出展しました。
ブースでは「Deep Learningを利用したハンドサイン画像認識のデモ」と「Deep Learningスターターキット」を展示し、多くの方に来訪していただきました。
本連載では、ブースで展示していました「Deep Learningを利用したハンドサイン画像認識のデモ」について、技術的な内容を含めて全三回に分けて解説します。
本記事は連載の第三回目となっています。
[第一回]Deep Learningとは、デモ概要、ハードウェア構成
[第二回]デモアプリケーション
[第三回]ハンドサイン画像の学習、当日の様子 (本記事)
ハンドサイン画像の学習
ハンドサイン画像を学習させるために、以下の手順で行いました。
- 学習用画像の収集
- 学習
- デモ当日に向けての調整
1. 学習用画像の収集
Deep learningで学習を行うには、大量のデータが必要となります。
今回のデモでは、当社所員5名に協力してもらい、各パターン約3,000枚の画像を集めました。それらの画像に輝度変化、拡大・縮小などの画像加工を施すことで10倍に水増しし、各パターン約30,000枚、全パターン合わせて約240,000枚の画像を集めました。
収集画像についての情報は以下のとおりです。
| 画像サイズ | 40 × 40 ピクセル、RGB 3チャンネル画像。 |
|---|---|
| パターン | 指の本数0本 ~ 5本 :6パターン。 NGパターン、背景の2パターンを合わせ、系8パターン。 |
| 元の枚数 | 各パターン約3,000枚。合計約24,000枚。 |
| 手のモデルとなった人数 | 5人 |
| 画像加工 | 輝度変化、回転、拡大・縮小、平行移動、少し歪ませる。 |
| 最終的な枚数 | 各パターン約30,000枚。合計約240,000枚。 |
学習させた画像の例。左から 0本、1本、…、5本、NGの一例、背景








2. 学習
Deep Learningによる学習では、Deep Learningフレームワークの一つである「Caffe」を利用して行いました。
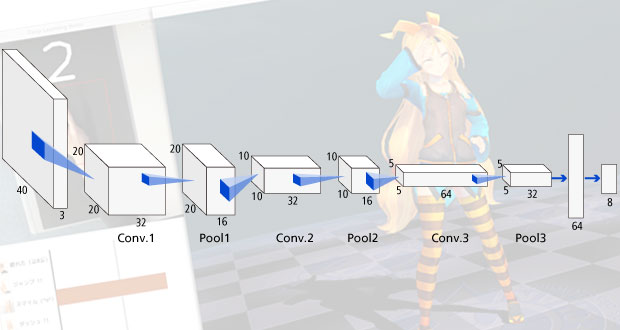
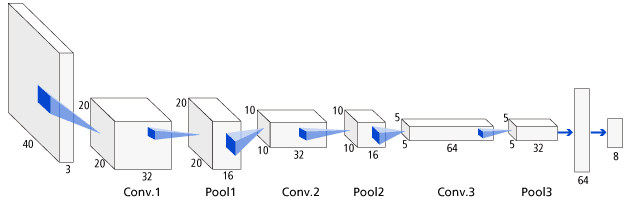
Deep Learningのレイヤー構成はCaffeのCifar-10サンプルにあるものを参照しました。「Convolution + Pooling」を1層として、3層 + 全結合層を合わせたものを利用しました。
レイヤー構成は以下のとおりです。
| No. | 層数 | 種類 | パラメータ | ニューロン数 |
|---|---|---|---|---|
| 0 | 0 | 入力 | 40 × 40 × 3 | |
| 1 | 1 | Convolution | Kernel = 5 ×5, Output = 32 Stride = 1, Pad = 2 |
20 × 20 × 32 |
| 2 | Pooling | Kernel = 3 × 3, Stride = 2 | 20 × 20 × 16 | |
| 3 | 2 | Convolution | Kernel = 5 ×5, Output = 32 Stride = 1, Pad = 2 |
10 × 10 × 32 |
| 4 | Pooling | Kernel = 3 × 3, Stride = 2 | 10 × 10 × 16 | |
| 5 | 3 | Convolution | Kernel = 5 ×5, Output = 64 Stride = 1, Pad = 2 |
5 × 5 × 64 |
| 6 | Pooling | Kernel = 3 × 3, Stride = 2 | 5 × 5 × 32 | |
| 7 | 4 | Inner product | Output = 64 | 64 |
| 8 | 5 | Inner product | Output = 8 | 8 |
3. デモ当日に向けての調整
デモ当日に向けては、ぎりぎりまで認識結果の向上に努めました。本番環境を用いて学習用画像を取得し、デモ本番環境で良い性能が出るように調整を繰り返しました。
TIPS
今回の環境での学習速度
今回のデモでは、ブースにて同時に展示を行っていたマシン「Deep Learningスターターキット」を利用して学習を行いました。(ハードウェア構成は第一回記事に記載しています。)
今回の学習では、1回の学習ごとに画像100枚ずつをレイヤーに流しました。学習誤差が0に近くなるまで約40,000回の学習を行い、13分程度で完了しました。

Deep learning スターターキット
デモの制約
今回のデモでは、当日多くの人の手を正しく認識していましたが、実はいくつかの制約がかかった状態で行われていました。
- 照明の制約
- 背景の制約
照明の制約
今回のデモを行うに際し、画像加工によりある程度輝度が変化したハンドサイン画像を学習させてはいたのですが、それでも、一定以上弱い、もしくは強い照明下では認識能力が低下してしまいました。
本格的に様々な条件の画像を与えて学習を行えば解決するのですが、今回は時間も限られているため、以下の対応策により問題を解消しました。
- カメラ側で輝度・ホワイトバランス等を調整。実験環境と本番環境をカメラ側設定により合わせる。
- 背景を黒にすることにより、照明によって発生する影の影響を下げる。
- カメラ上部に照明を取り付けられるようにし、本番環境が暗すぎる場合に対応できるようにする。
背景の制約
今回のデモでは、当初、カメラは前方に向ける想定でした。しかし、任意の背景からハンドサインを認識させるまでには至らず、グリーンバックやチラシの裏などの単一背景にはある程度対応していましたが、任意の背景には対応できませんでした。
そこで、実際にはカメラを下に向け、カメラの下に手を入れてもらう形でデモを行い、背景を黒に統一することで対応しました。
当日の様子
展示会当日は多くの方にブースを来訪していただき、ハンドサイン認識のデモを体験していただくことができました。
Deep Learningによる学習のもととなった手は5名分なのですが、多くの方のハンドサインを認識していました。少ない手の種類から正しくハンドサインの形状を学べていたことがわかり、改めてDeep learningの凄さを感じました。


まとめ
本記事では、ハンドサイン画像の学習についての解説を行いました。
5名分の画像を集めた結果で多くの人のハンドサインを正しく認識できるようになったのには驚きました。しかし、照明や背景の制約についてはデモ作成時間では解決できず、デモの外の環境への利用を考えると、解決すべき問題は多いようです。
今回までで全三回に渡り、ビッグデータEXPOで展示したDeep Learningを利用したデモについての解説を行いました。
Deep Learningは、大量のデータを与えることで、その特徴をコンピュータに学習させることができます。今回のデモでは、ハンドサイン画像による画像認識を展示しましたが、Deep Learning自体は様々なデータに応用できる技術です。
ISPでは今後も、機械学習やDeep Learningの情報を発信していきます。
- Deep Learningによるハンドサイン画像認識デモ 解説 (第一回)
- Deep Learningによるハンドサイン画像認識デモ 解説 (第二回)
- Deep Learningによるハンドサイン画像認識デモ 解説 (第三回)
今回のデモアプリケーションでは、キャラクターとして「ユニティちゃん」を使用しています。
