前回Data Augmentation手法としてのmixupの論文を紹介しました
[Data Augmentation 第1回] mixup 事始め
今回は少量データ(画像)の実験を行いましたのでそのご報告です。原論文のデータ・ラベル両方もmixと[2]で示されたデータのみのmixの両方を評価しました。
[原論文] mixup: Beyond Empirical Risk Minimization
https://openreview.net/forum?id=r1Ddp1-Rb [1]
http://www.inference.vc/mixup-data-dependent-data-augmentation/ [2]
1. 要約
- CIFAR10を使い少量データにおける mixup の効果を測定しました。
- ベータ分布の形は要調整ですが mixup は効果がありました。
2. 準備
CIFAR10 (データ量 50,000)のトレーニングデータの一部をいくつかのパターンで切り出し学習と計測を行いました。ファイルの切り出しはtrain.csv の先頭を抜きだしています。1クラスのあたりの枚数は不揃いです。抜き出した枚数のパターンと1クラスあたりの枚数の最小・最大は以下の通りとなります。
| 枚数 | min imgs/class | max imgs/class |
|---|---|---|
| 20,000 | 1925 | 2042 |
| 10,000 | 937 | 1032 |
| 5,000 | 460 | 520 |
| 1,000 | 85 | 112 |
| 500 | 40 | 65 |
| 250 | 18 | 35 |
| 100 | 4 | 16 |
3. 実験条件
使用したネットワークはResNet18 pre-act版です。以下の3つのパターンを評価しました。
| 名前 | 概要 | mixup 分布 | 補足 |
|---|---|---|---|
| non | mixup無し | NA | |
| data-mix | データのみ mix。 ラベルはmixしない。 |
Beta(2, 1) | 論文[1]+式変形[2]に従った |
| label-mix | データ・ラベルの両方を mixup (オリジナルの形式) |
Beta(1, 1) | 論文[1]に従った |
学習に関するパラメータは以下の通りです。
- mini-batch size は 128 で固定. base_lr は 0.1.
- 乱数の種は全実験で共通
- test のベストaccuracyを記述。後述するように、データ量が少ない時は過学習してしまう。
- epoch
- 1000 枚以上では 100 epoch 回し、33 epoch/66 epoch で lr を 1/10にした。
(パターンによっては少々 BP(Back Propagation) 少ない可能性あり)かも。 - 250 〜 1000 枚は 117000 iter(50000 枚時に 300 epoch 回したのと同じ回数 BP する)で固定した。
- 100枚の時は 40000 iter で 停止した。早々と収束しきってしまったため。
- 1000 枚以上では 100 epoch 回し、33 epoch/66 epoch で lr を 1/10にした。
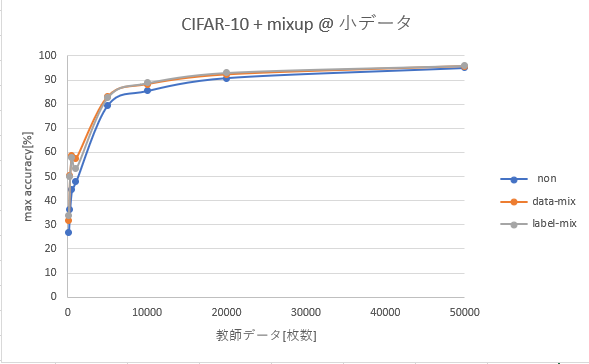
4. 実験結果
| 枚数 | non | data-mix | label-mix | 考察 |
|---|---|---|---|---|
| 50,000 | 95.00 | 95.71 | 96.00 | baseline |
| 20,000 | 90.81 | 92.26 | 93.09 | |
| 10,000 | 85.47 | 88.26 | 88.80 | |
| 5,000 | 79.52 | 83.16 | 82.86 | |
| 1,000 | 47.83 | 57.43 | 53.25 | 参考値。BP少ない |
| 500 | 44.60 | 58.59 | 57.84 | 117K iter |
| 250 | 36.34 | 50.29 | 50.08 | 117K iter |
| 100 | 26.79 | 31.72 | 33.84 | 40K iter |
データ数 vs 性能のプロット
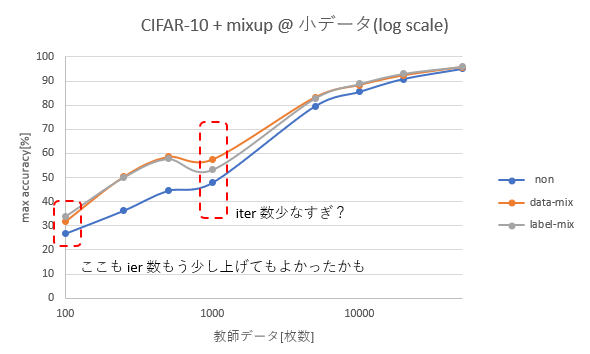
データ数を logスケールで表示
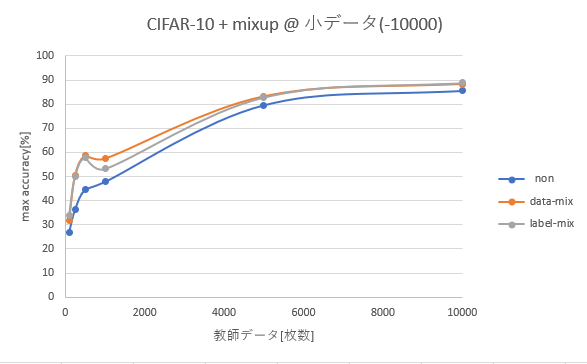
データ数 ~10000枚で絞った
5. 考察
- mixup のベータ分布はハイパーパラメータになるものの、データ量が少ない時でも mixup は有効に見える
- データ数 1000 の時に凹んでいるのは BP 数が少なすぎたためか。100 の時ももう少し多めに回した方が良さそう。
- データ数が少ない場合にカテゴリの偏りがあるので揃えた方が良かったかもしれない。
- 今回見た範囲ではdataのみのmix と data/label両方のmixのどちらが良いかは一概に言えない結果だった。
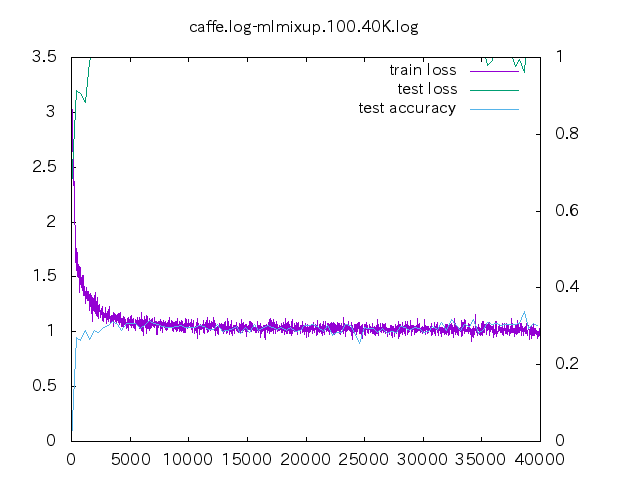
6. loss プロット
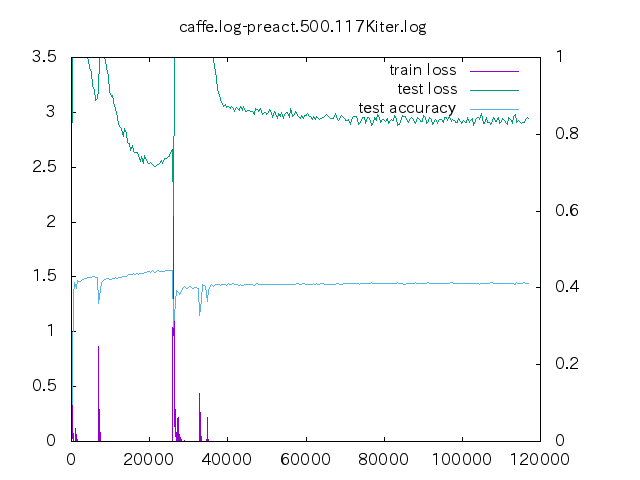
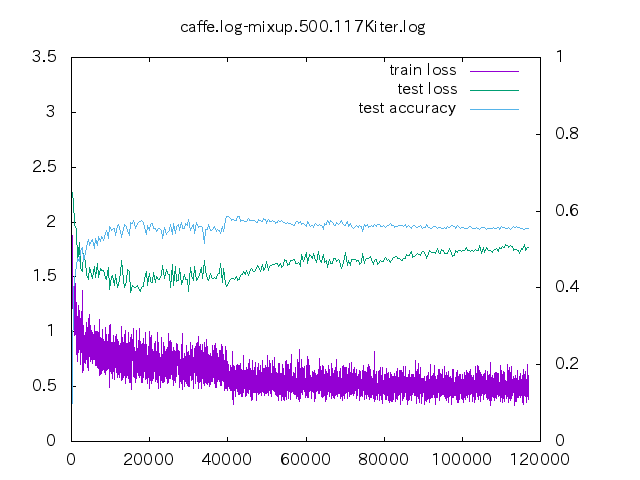
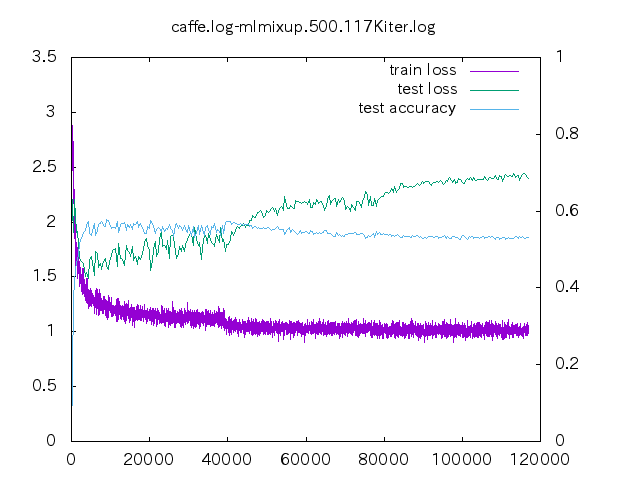
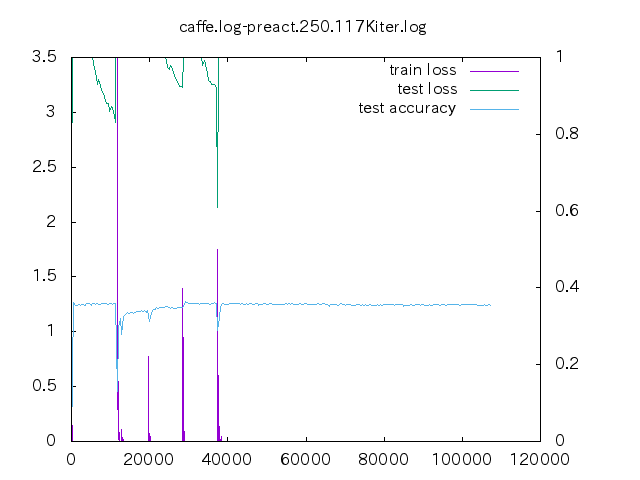
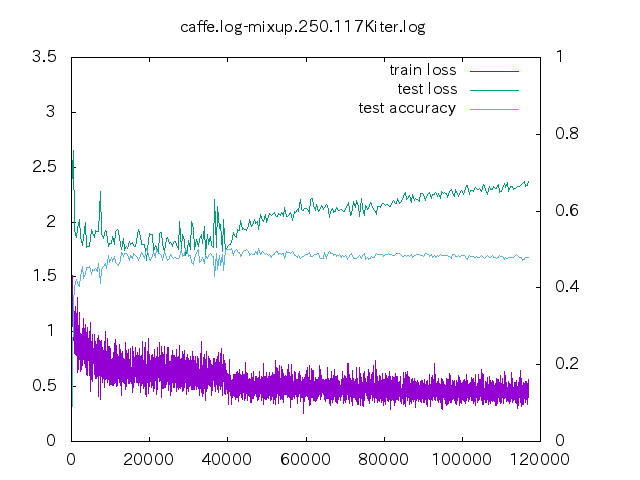
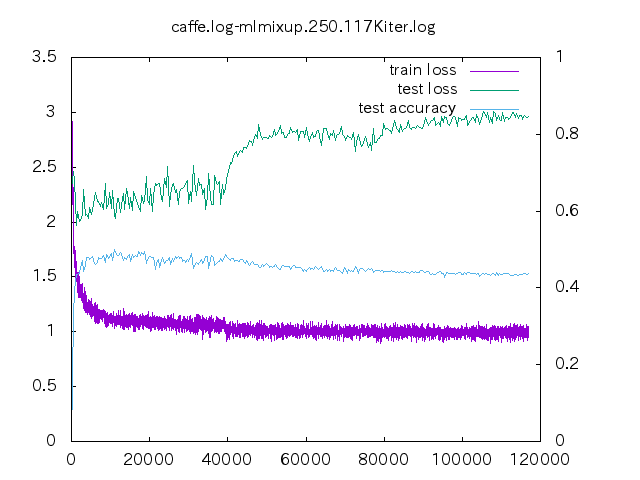
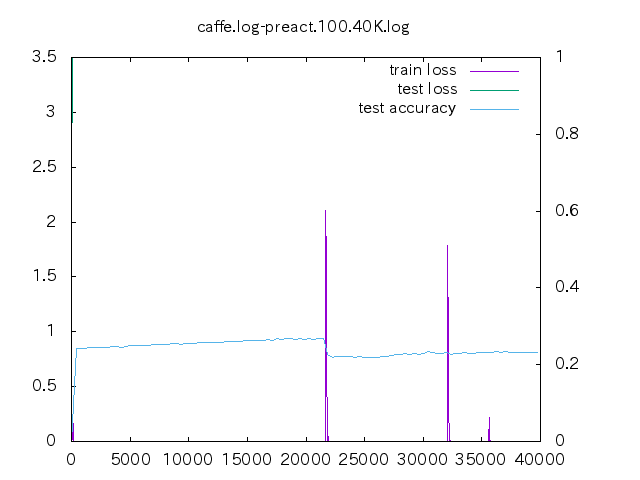
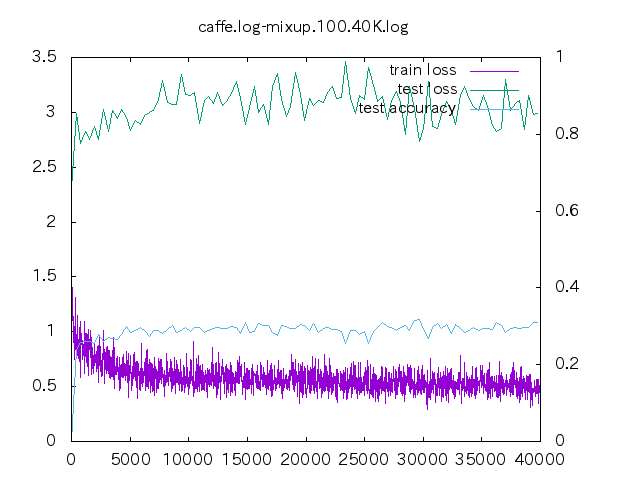
| 手法 | ||||
|---|---|---|---|---|
| non | data-mix | label-mix | ||
| デ | タ 量 |
500 | |||
| 250 | ||||
| 100 | ||||
- non はあっという間に収束してしまう。data-mix/label-mix 共に学習ロスは収束することは無い。
- mixup の場合、今の optimizer の設定だと過学習してしまっている。
- データ量が少ない時の置き込み方はノウハウが必要そう。
- label-mixup の方が割合を答える分難しく、学習ロスが下がらない。
[Data Augmentation 第1回] mixup 事始め