ここまでにData Augmentation手法のmixupに関する論文を紹介と少量画像データの実験結果を報告しました。
[Data Augmentation 第1回] mixup 事始め
[Data Augmentation 第2回] mixup 少量データでの効果測定(画像偏)
前回画像の少量データを扱いましたが、今回センサーデータについても実験してみました。原論文[1]のデータ・ラベル両方もmixと[2]で示されたデータのみのmixの両方を評価しています。
[原論文] mixup: Beyond Empirical Risk Minimization
https://openreview.net/forum?id=r1Ddp1-Rb [1]
http://www.inference.vc/mixup-data-dependent-data-augmentation/ [2]
1. 対象データ
今回はある対象物のセンサーデータの値です。データの提供元とのお約束でデータの素性を詳しく説明することができませんが、以下のようなデータです。
- 1データは1700次元のベクトル
- 各次元の値は0-1に正規化済み
- データの取得は大変で、80以上の種類のデータを提供いただけましたが、大半が1ラベル数個。
- トレーニングとテストのデータは必要なので、今回は1ラベル22以上の種類に限定。対象は7となった(データとしては8種あったが、そのうち1つは分類が正しくないことが判明したので除外)。データ数は以下の通り
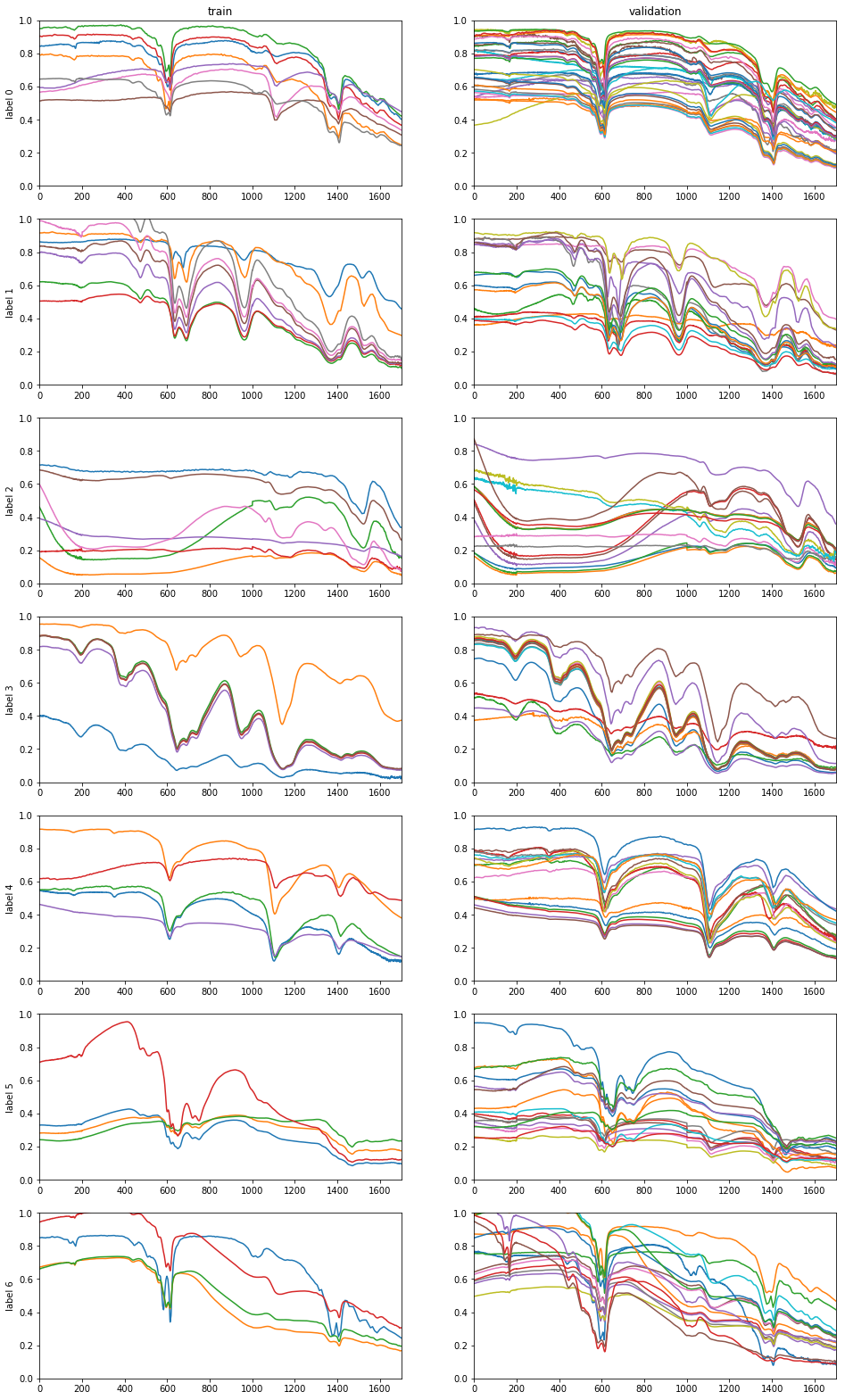
label データ数 0 42 1 27 2 27 3 23 4 22 5 22 6 22 - 図1はデータを可視化したもの。各行はラベル、左列は学習(train) 右列がテストとなっています。線1本が1つのデータです。
2. 実験
アプローチ
センサーデータは画像化してCNNで分類する方法も考えられますが、今回は数値のままMLPでの分類性能を評価しました。
モデル
3層、8層、12層で評価。各層の間にはDropout(レート0.2)を適用しました。
3層
| Layer (type) | Output Shape | Param # |
|---|---|---|
| dense_1 (Dense) | (None, 512) | 871424 |
| dropout_1 (Dropout) | (None, 512) | 0 |
| dense_2 (Dense) | (None, 512) | 262656 |
| dropout_2 (Dropout) | (None, 512) | 0 |
| dense_3 (Dense) | (None, 7) | 3591 |
| Total params: 1,137,671 Trainable params: 1,137,671 Non-trainable params: 0 |
||
8層
| Layer (type) | Output Shape | Param # |
|---|---|---|
| dense_1 (Dense) | (None, 512) | 871424 |
| dropout_1 (Dropout) | (None, 512) | 0 |
| dense_2 (Dense) | (None, 512) | 262656 |
| dropout_2 (Dropout) | (None, 512) | 0 |
| dense_3 (Dense) | (None, 256) | 131328 |
| dropout_3 (Dropout) | (None, 256) | 0 |
| dense_4 (Dense) | (None, 128) | 32896 |
| dropout_4 (Dropout) | (None, 128) | 0 |
| dense_5 (Dense) | (None, 128) | 16512 |
| dropout_5 (Dropout) | (None, 128) | 0 |
| dense_6 (Dense) | (None, 64) | 8256 |
| dropout_6 (Dropout) | (None, 64) | 0 |
| dense_7 (Dense) | (None, 64) | 4160 |
| dropout_7 (Dropout) | (None, 64) | 0 |
| dense_8 (Dense) | (None, 7) | 455 |
12層
| Layer (type) | Output Shape | Param # |
|---|---|---|
| dense_1 (Dense) | (None, 512) | 871424 |
| dropout_1 (Dropout) | (None, 512) | 0 |
| dense_2 (Dense) | (None, 512) | 262656 |
| dropout_2 (Dropout) | (None, 512) | 0 |
| dense_3 (Dense) | (None, 512) | 262656 |
| dropout_3 (Dropout) | (None, 512) | 0 |
| dense_4 (Dense) | (None, 256) | 131328 |
| dropout_4 (Dropout) | (None, 256) | 0 |
| dense_5 (Dense) | (None, 256) | 65792 |
| dropout_5 (Dropout) | (None, 256) | 0 |
| dense_6 (Dense) | (None, 128) | 32896 |
| dropout_6 (Dropout) | (None, 128) | 0 |
| dense_7 (Dense) | (None, 128) | 16512 |
| dropout_7 (Dropout) | (None, 128) | 0 |
| dense_8 (Dense) | (None, 128) | 16512 |
| dropout_8 (Dropout) | (None, 128) | 0 |
| dense_9 (Dense) | (None, 64) | 8256 |
| dropout_9 (Dropout) | (None, 64) | 0 |
| dense_10 (Dense) | (None, 64) | 4160 |
| dropout_10 (Dropout) | (None, 64) | 0 |
| dense_11 (Dense) | (None, 64) | 4160 |
| dropout_11 (Dropout) | (None, 64) | 0 |
| dense_12 (Dense) | (None, 7) | 455 |
| Total params: 1,676,807 Trainable params: 1,676,807 Non-trainable params: 0 |
||
学習データ・テストデータ・cross-validation
5-fold cross-validationで評価しました。但し、少量データ学習の効果を測りたいたかったため、通常の取り扱い方とは逆に分割した少ない方を学習に、多い方をテスト(validation)に使用しました。なお、層化(Stratification)を施し各回概ねクラスあたりのデータ数が均衡するようにしました。
学習パラメータ
- オプティマイザーはAdadelta。パラメターはKeras規定値
- mini-batch size は 32 で固定
- epoch数は最大500としてEearly Stoppingによる打ち切り
データ・ラベルのmixとデータのみのmix
[1]に従ったデータ・ラベルの両方のmix及び[2]のデータのみのmixの双方を評価しています。
α
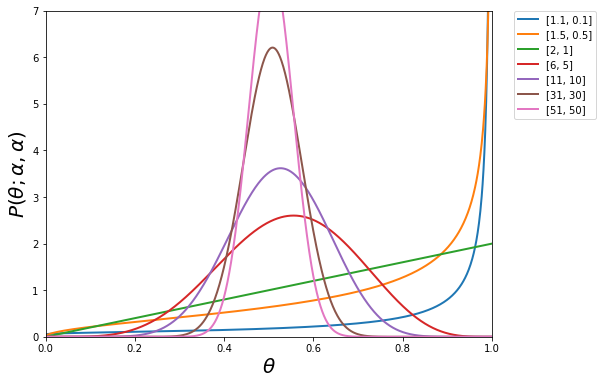
mixupは以下のようにデータを生成するのでBeta分布のαがハイパーパラメータです。
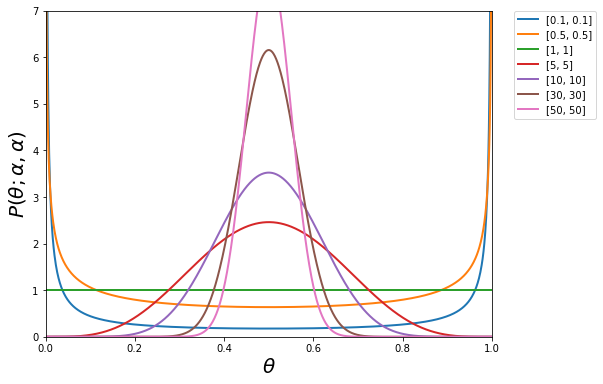
αについては以下の22パターンを評価した。
0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 50
この場合のBeta分布は以下の形状となります(抜粋)。
[2]のデータのみmixの場合は、上記のパターンで左項をプラス1しています。形状は以下の通りです。
3. 結果
実験のパターンは135(α 22/mix type2/モデルサイズ3 +mixなしでのモデルサイズ3パターン)です。
平均accuracy
5 fold cross-validationのvalidate accuracyの平均を降順に並べると以下の通りとなりました(抜粋)
| 順位 | mean | max | min | std | α | mixup | mix type | model |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.900 | 0.920 | 0.841 | 0.034 | 1.0 | 1 | 0 | 0 |
| 2 | 0.899 | 0.922 | 0.833 | 0.037 | 0.8 | 1 | 0 | 0 |
| 3 | 0.894 | 0.928 | 0.826 | 0.040 | 0.2 | 1 | 0 | 0 |
| 4 | 0.893 | 0.906 | 0.848 | 0.025 | 0.3 | 1 | 0 | 0 |
| 5 | 0.893 | 0.913 | 0.855 | 0.024 | 0.7 | 1 | 0 | 0 |
| 6 | 0.890 | 0.914 | 0.841 | 0.032 | 8.0 | 1 | 0 | 0 |
| 7 | 0.890 | 0.906 | 0.833 | 0.032 | 0.1 | 1 | 0 | 0 |
| 8 | 0.890 | 0.913 | 0.841 | 0.029 | 6.0 | 1 | 0 | 0 |
| 9 | 0.888 | 0.920 | 0.862 | 0.026 | 0.9 | 1 | 0 | 0 |
| 10 | 0.888 | 0.945 | 0.804 | 0.052 | 0.6 | 1 | 0 | 0 |
| • • • | ||||||||
| 34 | 0.853 | 0.920 | 0.775 | 0.054 | – | – | – | – |
| 48 | 0.764 | 0.828 | 0.674 | 0.057 | – | – | – | 1 |
| 76 | 0.561 | 0.734 | 0.420 | 0.118 | – | – | – | 2 |
| • • • | ||||||||
| 135 | 0.373 | 0.461 | 0.254 | 0.076 | 30.0 | 1 | 1 | 2 |
| 順位: | meanをキーとしたときの順位 |
| mean: | 5 fold cross-validationのvalidate accuracyの平均 |
| max: | 5 fold cross-validationのvalidate accuracyの最大 |
| min: | 5 fold cross-validationのvalidate accuracyの最小 |
| std: | 5 fold cross-validationのvalidate accuracyの標準偏差 |
| α: | αのパターン |
| mixup: | 1がmixup適用。0は未適用 |
| mix type: | 0はdataとラベルの両方をmix,1はdataのみをmix |
| model: | モデルの種類。0:3層、1:8層、 2:12層 |
上位を独占したのはデータとラベルの両方をmixした、小さいモデル(3層)のものでした。最良の組み合わせはα=1で平均accuracyが0.9でした。載せてはありませんが、中央値ソートでもこの組み合わせが最良となりました。
mixup適用なしで最良だったのもやはりモデルサイズ小で、平均accuracyが0,853。思ったよりは高い性能が出ていました。
モデルサイズ
各モデルサイズのmixup適用上位3つと、mixup適用無しを抜き出してみました。
| 順位 | mean | max | min | std | α | mixup | mix type | model |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.900 | 0.920 | 0.841 | 0.034 | 1.0 | 1 | 0 | 0 |
| 2 | 0.899 | 0.922 | 0.833 | 0.037 | 0.8 | 1 | 0 | 0 |
| 3 | 0.894 | 0.928 | 0.826 | 0.040 | 0.2 | 1 | 0 | 0 |
| 34 | 0.853 | 0.920 | 0.775 | 0.054 | 1.0 | 0 | 0 | 0 |
| 46 | 0.780 | 0.891 | 0.696 | 0.082 | 0.1 | 1 | 0 | 1 |
| 47 | 0.777 | 0.922 | 0.710 | 0.083 | 0.4 | 1 | 0 | 1 |
| 48 | 0.764 | 0.828 | 0.674 | 0.057 | 1.0 | 0 | 0 | 1 |
| 49 | 0.749 | 0.953 | 0.594 | 0.140 | 0.5 | 1 | 0 | 1 |
| 74 | 0.569 | 0.656 | 0.486 | 0.062 | 0.1 | 1 | 0 | 2 |
| 76 | 0.561 | 0.734 | 0.420 | 0.118 | 1.0 | 0 | 0 | 2 |
| 78 | 0.560 | 0.630 | 0.486 | 0.066 | 0.5 | 1 | 0 | 2 |
| 79 | 0.559 | 0.648 | 0.478 | 0.075 | 0.7 | 1 | 0 | 2 |
性能は見事にモデルサイズ順の結果となりました。
αとaccuracyとの関係
αとmean accuracyの関係をグラフ化しました。対象はモデルサイズ小でラベル・データ両方のmix(青)とデータのみmix(赤)です。
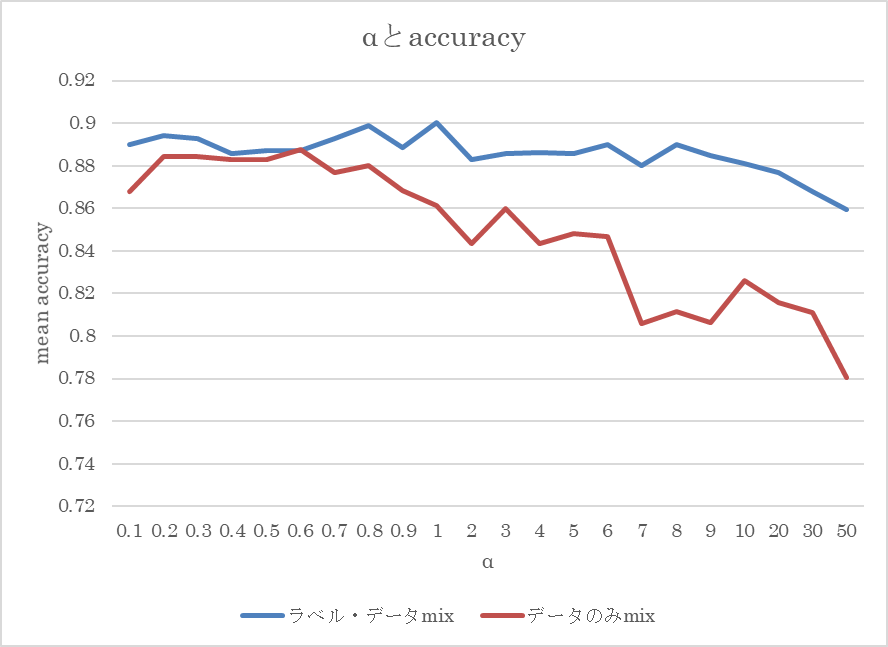
αが大きくなると中央が高くなりますので、問題としては難しくなるものと思われます。ラベル・データの両方をmixした場合、α=50ですらmixup無しの性能を上回っており、比較的影響が抑え込まれているように思います。データのみのmixの場合は流石に性能の低下傾向が見て取れました。
4. 結論
センサーデータに対してもmixupは有効でした。センサーデータの場合、ドメイン知識なしでのData Augmentationが困難ですので、機械的にデータを増やすことのできるmixupは手法として有用と言えるでしょう。
[Data Augmentation 第1回] mixup 事始め
[Data Augmentation 第2回] mixup 少量データでの効果測定(画像偏)