M2Mでは「機器数 × 通信頻度 × 1回あたりのデータ量」でデータ量が増えていきます。このようなビッグデータを扱う技術には様々な物がありますが、ここでは一例として大規模分散処理基盤Hadoopについて説明します。
by wazalabo-editor 2013/08/26
大規模分散処理基盤「Hadoop」
ビッグデータ技術は、検索エンジンで有名な Google 社による分散ファイルシステムと、そのデータに対する計算を分散して行う MapReduce と呼ばれるプログラミングモデルについての論文を皮切りに、2004年前後から急速に発展してきました。
Hadoop は、この論文を参考に開発されたオープンソースの大規模分散処理基盤です。当初は、インターネット上に存在する膨大な数の Web サイトの情報を集めて解析する Web 検索エンジンのために作られた技術基盤なのですが、その汎用性から単独のプロジェクトとして独立し、現在に至っています。
Hadoop の開発には、Yahoo! や Facebook などの有名企業のチームも参加しており、それぞれ自社のビッグデータ解析に活用しています。国内でもWeb業界の企業でデータ解析用途に採用されるなど、普及が進んでいます。
先ほど挙げたビッグデータを扱う上での課題を振り返りますと、Hadoop ではデータの保持と分析処理を複数のコンピュータに分散させることで、それぞれの性能課題を解決しています。また、データのコピーを異なるコンピュータに分散して記録することで、仮に一部のコンピュータに障害が発生してもデータが壊れることはありません。

分散ファイルシステムはHDFSと呼ばれ、ファイルを分割して複数のサーバに分散して保持します。巨大なサイズのファイルが扱えるようになる一方、ファイルの更新は追記しかできないなど、いくつかの制限があります。データ検索が必要な場合は、 HBase と呼ばれるデータベースが使えます。データの一行一行を、「検索キー vs 値」という形で保存しており、検索キーによるデータ行の取り出しが容易に行えます。
MapReduce(分散計算処理)とは?
MapReduceとは、ビッグデータを分散して処理するプログラミングモデルです。キーと値のペアが、基本的なデータ構造となります。簡略するために、以下「Key-Value」と記載します。
MapReduceの基本的なアイデアとしては、入力情報をKey-Valueとして受け取り、Map処理で中間Key-Valueを出力、Reduce 処理では中間Key-ValueのKeyでデータを束ねて、なんらかの集計・計算を行います。
下記に、単純な例を示します。入力は人名をキーとした情報で、 Map処理でこれを生まれ年をKeyとしたデータに変換します。最後に Reduce処理 で生まれ年ごとにデータを束ねて各年に生まれた人の数を集計します。

Hadoop を使ったデータ解析では、まず処理の内容を上記の MapReduce ステップの形に落とし込む必要があります。MapReduce を行うプログラムはジョブと呼ばれ、自作することもできれば、Hive や Pig といった Hadoop のモジュールを使ってSQL風の言語や簡単な命令文を書き、自動生成させることもできます。
このほかにも、Mahout と呼ばれる機械学習のサブプロジェクトもあり、高度なデータ分析を容易に行うことができます。
Hadoopクラスタを構築するには
MapReduceを実行する前の段階で、Hadoopクラスタを構築する必要があります。サーバには、安価なマシンを組み合わせるとはいえ、マルチコア(4コア以上は必要です)、メモリは少なくとも十数GB以上のものが必要です。サーバ1台でも構築することは可能ですが、通常は複数台のサーバが必要です。
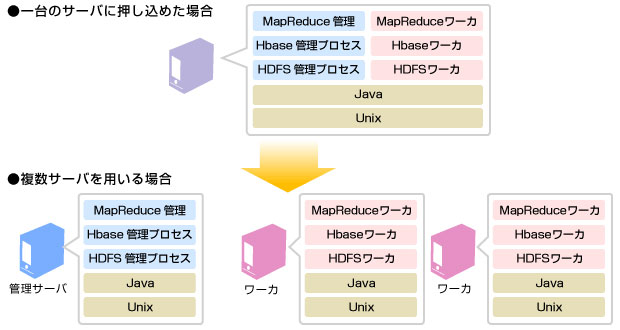
次にソフトウェア面ですが、Hadoopはlinuxサーバ上で実行される複数のjavaプログラムからなります。これらはHDFS・MapReduceの2層からなり、いずれも管理プロセスが一つと、複数のワーカー型プロセスからなります。HBaseを利用する場合は、さらにHBase用のプロセスも必要です。
Hadoopクラスタを構築した後、各サーバに実行したいジョブのjarファイル(exeのようなものです)、および、入力データファイルを配置してJobを実行します。
以上を踏まえると、以下のようなシステム構成になります。1台のサーバにこれらのプロセスを押し込めることも可能ですが、クラスタを組む場合はワーカー用にサーバを複数台用意します。インストール手順については省略しますが、サーバの調達・インストール・ミドルウェアの構築がかなり大変なことが想像できるかと思います。
クラウドのHadoop環境を使うと、構築済みのHadoopクラスタすぐに使うことができるため、評価目的の導入や小さい規模でプロジェクトを始めることができます。

次章では、クラウドHadoop環境の一つである「Amazon EMR」を例に、契約から本サービスを利用して支払いを行うまでのプロセスを解説します。