連載第3回では、「Amazon EC2」に代表されるクラウドサービスを利用して、手軽にMapReduce処理を実行する環境を構築できる方法を、皆様にご紹介します。
by wazalabo-editor 2013/09/04
話題の「ビッグデータ」をテーマに、大規模分散処理技術や事例、システム設計手法などをご紹介するスペシャル企画。その第3回では、クラウドHadoop環境の一つである「Amazon EMR」を例に、契約から本サービスを利用した決済までのプロセスを解説します。
クラウドを用いた分散処理のメリット
まず、第2回で解説しました「MapReduce」と「Hadoop」のおさらいをしておきましょう。MapReduceとは、ビッグデータを分散して処理するプログラミングモデルのことでしたね。このモデルを実際に活用してビッグデータ解析を行うためには、オープンソースの大規模分散処理基盤「Hadoop」が必要になります。ソースコードが公開されており、もちろん導入手順に関する情報も公開されていますから、自前でサーバを用意して、Hadoopによる分散処理基盤を作成することが可能です。
ただし、そのためにはHadoopの要求スペックを満たすサーバ機を、複数台準備する必要があります。また、導入手順が整備されているとはいえ、Hadoop環境を整備・運用するには、Hadoopの操作に関してある程度習熟していなければなりません。この課題を解決するためには、「Amazon EC2」に代表されるクラウドサービスを利用して、手軽にMapReduce処理を実行する環境を構築するという方法があります。
Amazon.comは、ElasticMapReduce(EMR)というサービスをPaaS(*)として提供しています。Amazon EMRは、インスタンス数・インスタンス利用時間・データ転送量などに応じて従量制で課金されるサービス体系ですので、「とりあえずMapReduceを試したい」というケースや、「数十台のハイスペックなサーバ群で構築し、本格的な解析を実施したい」という場合にも、おすすめできるサービスです。
「技ラボ編集部」では、この記事を作成するために、実際に作成したMapReduce Jobを、Amazon EMR上で実行しています。その際の手順と、稼働させた場合に発生する料金を、今回ご紹介します。インターネット上では、MapReduce JobをJavaで自作して動作させる方法(EMRでは”CustomJar”という用語で呼称されています)については、まとまった情報が公開されてないようですので、こうした点についての記述も、この「第3回」では充実させています。
(*)Platform as a Serviceの略。アプリケーションソフトを稼動させるためのハードウェアやOSなど、基盤(プラットフォーム)一式を、インターネット上のサービスとして遠隔から利用できるようにしたもの。
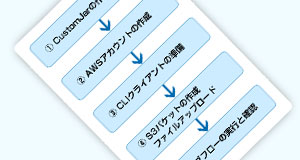
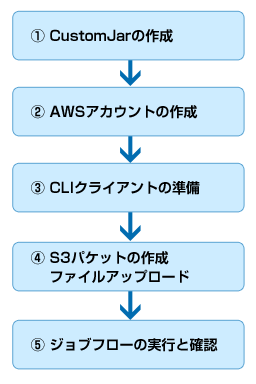
CustomJarを用いたEMR操作は、おおまかに以下のステップで進めることができます。
- まず、動作させるMapReduceを実装したJarファイルを作成します。
- 次に、AWSアカウントを作成し、EMRを実行できるクラウド環境を準備します。
- その後、ローカルにCLIクライアント環境を整えます。ここでは、設定ファイルや認証ファイルを準備する必要があります。
- MapReduceのJarファイルや入出力ファイルをアップロードするためのファイル置き場である、S3バケットを作成し、必要なファイルをアップロードします。
- その後、いよいよEMRのジョブフローを作成・実行し、実行結果や実行に要した料金などを確認します。
(1) CustomJarの作成
まずはeclipseにて、シェアカウントプログラムを作成します。その際に利用したライブラリは、以下のものです。
●hadoop-core-1.0.3,jar
●commons-cli-1.2.jar
●commons-configuration-1.9.jar
●commons-lang-2.6.jar
●commons-logging-1.1.3.jar
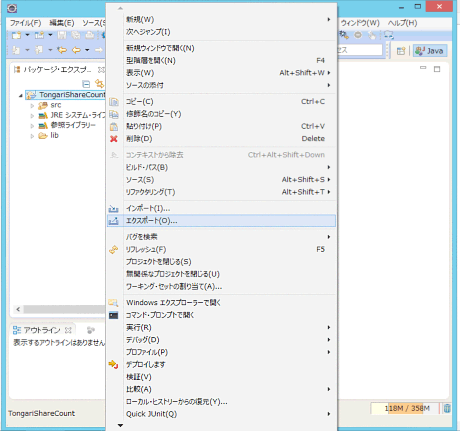
エクスポートするときは、プロジェクトを右クリック⇒エクスポート⇒JARファイルを選択してください。
<Note>
Amazon EMRでは、実行できるMapReduce JobのHadoopバージョンに制限があります。 この記事の執筆時点(2013年7月)では、EMRが対応しているHadoopバーションは以下です。
● 1.0.3
● 0.20.205
● 0.20
● 0.18
必ず対応するバーションのhadoop-coreライブラリを用いるようにしてください。
(2) AWSアカウントの作成
http://aws.amazon.com/ にアクセスし、Amazon Web Service(AWS)アカウントを作成します。
アカウント作成は、以下の画面から開始します。すでにAmazonアカウントをお持ちの方は、お持ちのアカウントを利用することも可能です。
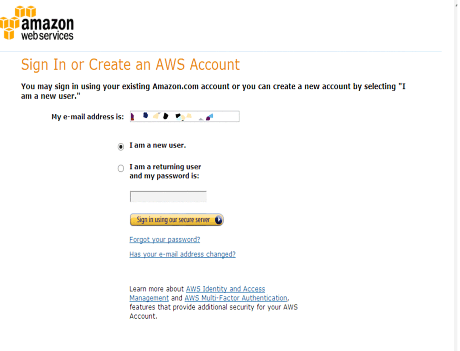
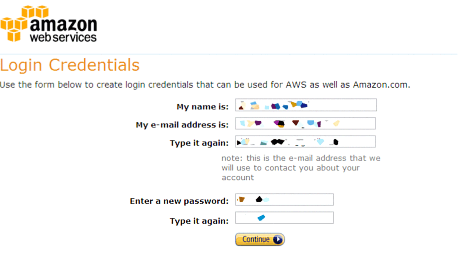
▲氏名、メールアドレス、パスワードを入力します。

▲次に、氏名・住所などのお問い合わせ情報を入力します。内容は半角英数字で入力してください。
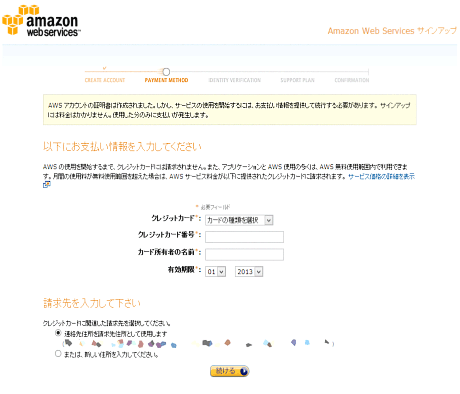
▲クレジットカード情報、および請求先を入力します。
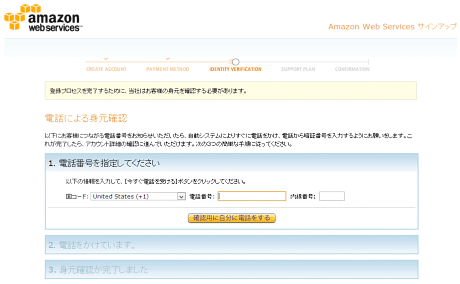
▲次に、電話認証を行います。
国コードで「Japan」を選択し、電話を受けられる電話番号を入力してください。「確認用に自分に電話をする」をクリックすると、WEB画面に4桁の確認番号が表示されます。程なくしてamazonから自動音声で確認番号の入力を促す電話がかかってきますので、電話機で確認番号を入力してください。
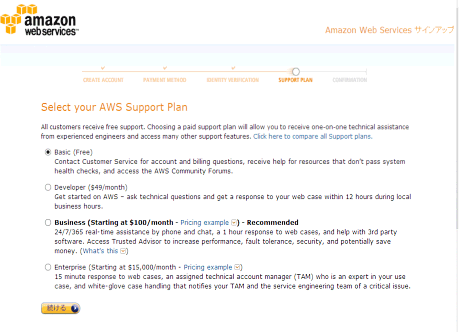
▲次にサポートプランの選択画面に移ります。Basicを選択してください。
以上でAWSアカウントが作成できました。
(3) CLIクライアントの準備
EMRはWEBインターフェイス経由で操作できるのですが、CLIクライアントを用いて操作したほうが、操作ミスも防げる上にAWS操作も自動化できるため、都合がよい場合があります。そのため、今回はローカルのubuntu環境にCLIクライアントを導入する操作を中心に解説します。
AWSは、EMRのすべての操作でREST APIを提供しています。コマンドラインから、そのREST APIを叩くCLIクライアントである公式のruby製ラッパースクリプトがあるので、それを動かすための環境設定をしましょう。
以下は、ubuntu環境のクライアントからの操作です。
rubyのインストール
rubyをインストールします。
$ sudo apt-get install ruby-fullAmazon EMR CLIのダウンロード
Amazon EMR CLI(公式のラッパースクリプト(ZIP圧縮))を、以下のURLからダウンロードします。
http://aws.amazon.com/developertools/2264
利用したいフォルダを作成し、その中に展開します。

zipファイルを展開したディレクトリは上記のようになっています。
赤字の部分は設定ファイルで、unzipした中には含まれていません。この2つのファイルは、CLI設定や認証情報を含んだもので、いくつかのWEBインターフェイスを操作して作成していく必要があります。.pemファイルの作成方法に関しては、付録(B)をご参照ください。
認証情報ファイルの作成
credentials.jsonという名前の、以下のようなJsonファイルを新規作成します。
[サンプル]
{
"access_id": "Your AWS Access Key ID",
"private_key": "Your AWS Secret Access Key",
"keypair": "Your key pair name",
"key-pair-file": "The path and name of your PEM file",
"log_uri": "A path to a bucket you own on Amazon S3, such as, s3n://mylog-uri/",
"region": "The region of your job flow, either us-east-1, us-west-2, us-west-1, eu-west-1, ap-northeast-1, ap-southeast-1, ap-southeast-2, or sa-east-1"
}| access_id | AWS アクセスキー ID(作成・確認方法は付録Aを参照) |
|---|---|
| private_key | AWS シークレットアクセスキー(作成・確認方法は付録Aを参照) |
| keypair | Amazon EC2 キーペア(作成・確認方法は付録Bを参照) |
| key-pair-file | Amazon EC2 キーペアファイルパス(作成・確認方法は付録Bを参照) |
| log_uri | ジョブフロー結果およびログを格納するS3のURL |
| region | ジョブフローを実行するリージョン。東京は”ap-northeast-1” |
CLIクライアントが正常に動作するかを確認するためには、以下のコマンドで正常にバージョンが表示されればOKです。
$ ./elastic-mapreduce --version
Version 2013-03-19公式ドキュメントでは、これだけで実行できるとのことでしたが、手元の環境では、「OpenSSL系のライブラリが見つからない」というエラーが起きました。
(/amazon/coral/v0signaturehandler.rb:4:in `require’: no such file to load — openssl (LoadError))。
この対策として、以下のコマンドでOpenSSLライブラリを追加インストールしています。
$ sudo apt-get install libopenssl-ruby1.8(4) S3バケットの作成・ファイルアップロード
credential.jsonの“log-uri”パラメータは、Amazon S3のどの場所にジョブフロー出力ファイルを格納するかを設定します。そのために、まずはAmazon S3バケットを作成する必要があります。
<Amazon S3とは>
安価かつ高い耐久性(99.999999999%)を持つオンラインストレージサービスです。最初の1TBまではGB単価$0.1/月で利用可能な従量課金がベースで、それ以外にもリクエスト単位、データ転送単位で課金が発生します(参考: http://aws.amazon.com/jp/s3/pricing/ )。
ただし、同一リージョンのEMRで利用する限りは、データ転送料金はありません。また、リクエスト料金とストレージ料金も非常に安価であるため、通常の使い方であればコスト面では大きな負担となることはありません。
<バケットとは>
「バケツ」のことです。オブジェクト(S3上に置くファイルのこと)を置くことができるまとまりで、1アカウントあたり100個までバケットを作成可能です。バケットに置くことができるオブジェクト数に制限はありません。オブジェクトのサイズは5TBまでの制限があります。バケットやオブジェクト単位で、アクセス制限をかけることができます。
では、S3バケットを作成しましょう。S3マネジメントコンソール(https://console.aws.amazon.com/s3/)を開きます。
その後、「Create Bucket」ボタンをクリックし、新規バケットを作成します。
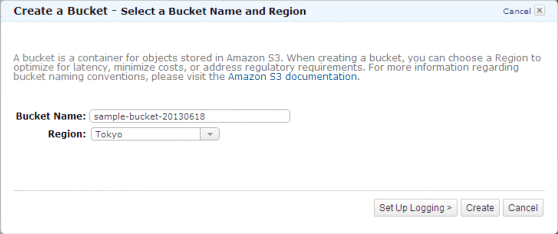
一度作成したBucket Nameは変更できず、またグローバルに一意である必要があります(つまり、シンプルな名前だと重複します)。
次に、バケットを保持するリージョンを選択します。通常はEMRを実行するリージョンです。
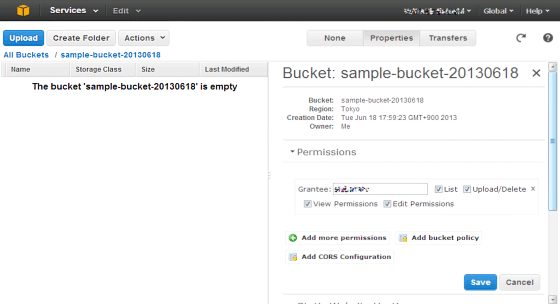
「Create」をクリックすると、S3マネージメントコンソールのトップ画面に戻ります。新規に作成したバケットが出現しますので、クリックするとバケットの内部を覗くことができます。この画面は、まだ何もファイルがない状態です。右側の上部に「None」「Properties」「Transfers」というボタンがありますから、「Properties」を選択すると、「Permissions」タブで権限が設定できます。
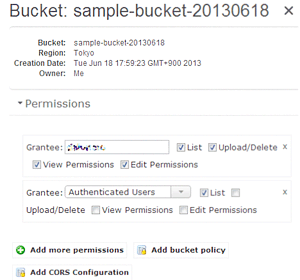
「Add more permissions」をクリックし、Garanteeで「Authenticated Users」を選択して右のチェックボックスで「List」にチェックを入れます。
これで、新規作成したバケットにEMRのジョブフローからアクセスできるようになります。
credentials.jsonの”log-uri”パラメータには、”s3n://<バケット名>/”を指定します。
次に、EMRフォブフローから入出力するオブジェクトのためのフォルダを作成します。
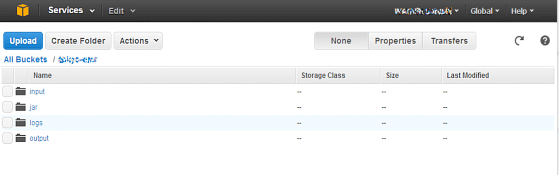
▲上の画面のように、4つのフォルダを作成します。
| input | 入力データを格納するフォルダ |
|---|---|
| output | 出力データを格納するフォルダ |
| logs | ログを格納するフォルダ |
| jar | 実行するjarを格納するフォルダ |
inputフォルダを選択し、左上のUploadボタンを押下することで、ローカルマシン上のインプットファイルをS3上にアップロードすることができます。ここでは、「movie_genre_rating.csv」をアップロードします。また、jarフォルダを選択し、左上のUploadボタンを押し、作成した「TongariShareCount.jar」をアップロードします。
以上で、EMRジョブフローを動かすための準備は完了です。
(5) ジョブフローの実行と確認
コマンドラインから、jarファイルおよび入力データのS3アドレスと、出力データのS3アドレスを指定して、ジョブフローを作成・実行します。
$ ./elastic-mapreduce \
--create \
--name “TongariSC01” \
--num-instances 1 \
--instance-type m1.large \
--jar s3:///jar/TongariShareCount.jar \
--arg s3:///input \
--arg s3:///output \
--log-uri s3:///logs上記コマンドでは、ジョブフロー名「TongariSC01」、m1.largeインスタンスx1のジョブフローを作成して実行しています。
実行に成功すると、ユニークに生成されたジョブフローIDが返却されます。
ジョブフローの確認
ジョブフローの状態を確認するためには、Elastic MapReduce Console https://console.aws.amazon.com/elasticmapreduce/ にアクセスします。
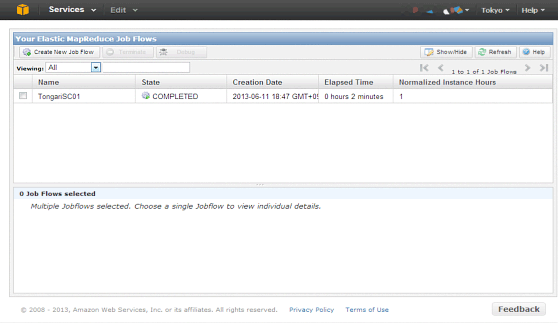
Statusは、STARTING → RUNNING → COMPLETEDに遷移します。
ジョブフローを選択することで、ジョブフローの詳細情報やモニタリング情報を表示することができます。
詳細情報で取得できるものは以下の種類です。
- ジョブフロー情報
- ジョブフロー名
- ジョブフロー作成時刻
- ジョブフロー開始時刻
- ジョブフロー終了時刻
- 実行リージョン
- インスタンス数
- マスターノードインスタンスタイプ
- スレーブノードインスタンスタイプ
- キーペア名
- ログURL
- AMIバージョン
- MasterPublicDNS名
- Hadoopバージョン
- Keep Alive有効無効
- Termination Protected有効無効
- VisibleToAllUsers有効無効
- サブネットID
- Supported Products
- ステップ情報
- ステップ名
- ステップ状態
- 開始時刻
- 終了時刻
- JarファイルURL
- Mainクラス名
- コマンドライン引数
- BootstapActions情報
- アクション名
- Path
- コマンドライン引数
- インスタンスグループ情報
- インスタンスグループID
- マスター/スレーブ
- インスタンスタイプ
- インスタンス状態
- インスタンス起動方法
- 入札価格(起動方法がスポットの場合のみ)
- 実行中インスタンス数
- 要求インスタンス数
- 作成時刻
- 最新の状態
- モニタリング情報(リアルタイムでグラフ表示)
- Avg Map Tasks Running (count)
- Avg Map Slots Open (count)
- Avg Map Tasks Remaining (count)
- Avg Remaining Map Tasks / Slot (count)
- Avg Reduce Tasks Running (count)
- Avg Reduce Tasks Remaining ‘(count)
- Avg Reduce Slots Open (count)
- Avg HDFS Utilization (percent)
- Avg Missing Blockes (count)
- Avg Jobs Running (count)
- Avg Jobs Failed (count)
- Avg Is Idle? (count)
- Avg Core Nodes Running (count)
- Avg Core Nodes Pending (count)
- Avg Task Nodes Running (count)
- Avg Task Nodes Pending (count)
- Avg Live Data Nodes (count)
- Avg Live Task Trackers (count)
- Avg S3 Bytes Written (count)
- Avg S3 Bytes Read (count)
- Avg HDFS Read (count)
- Avg HDFS Written (count)
実行結果の確認
Elastic MapReduce Console上で、ジョブフローが「COMPLETED」になれば、ジョブフローは完了しています。ログ出力や結果出力がS3に反映されるためには、若干のタイムラグがありますので、少し待ってからS3 Console https://console.aws.amazon.com/s3/ にアクセスします。
ログフォルダの中には、以下のようなログが記録されます。

結果フォルダには、以下のファイルが記録されます。

ジョブフロー実行にかかった金額を確認するには、アカウント情報から、アカウントアクティビティを選択します。
今回の記事作成にあたって、「技ラボ編集部」はジョブフローの実行に計2回失敗しており(m1.smallインスタンス1回 / m1.largeインスタンス1回)、ようやく3度目(m1.largeインスタンス)に成功しています。
なお、この試行錯誤にかかった費用の総額は、以下の通りでした(料金体系は2013年4月時点のものです)。
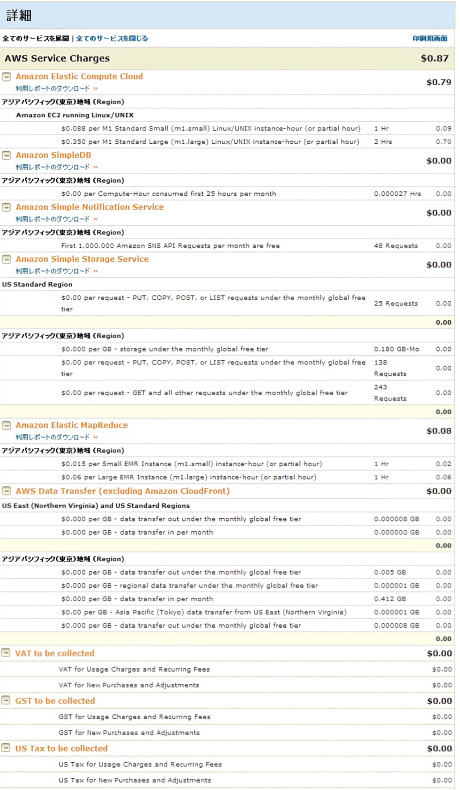
料金が発生したのは、Amazon Elastic Compute Cloud(EC2)、およびAmazon Elastic MapReduce(EMR)の2つのサービスで、日本円に換算して100円に満たない程度の料金でした。
付録
(A)AWSアクセスキー・AWSシークレットアクセスキー情報
AWSにログインし、「アカウント/コンソール」ドロップダウンメニューから「アカウント」を選択します。
アカウント画面の左メニューから、「セキュリティ証明書」を選択します。
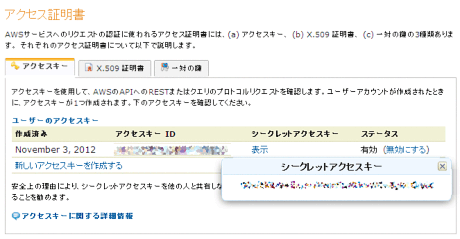
「アクセスキー」タブから「新しいアクセスキーを作成する」をクリックし、ダイアログを進めると、ユーザのアクセスキー一覧に、アクセスキー情報が表示されます。アクセスキーIDがcredencials.jsonの”access_id”パラメータにあたり、シークレットアクセスキーが”private_key”パタメータにあたります。
(B)Amazon EC2キーペアの作成・SSH認証情報の設定
AWSマネジメントコンソール(https://console.aws.amazon.com/ec2/)を開きます。
その際、左上メニューから、利用するリージョンを選択します(この場合はAsia Paciffic(Tokyo))。
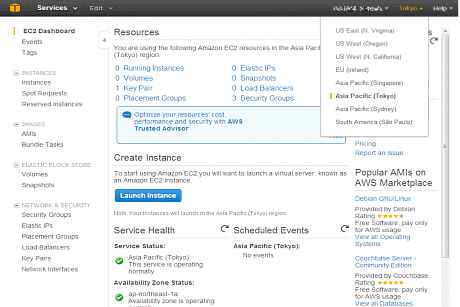
その後、左メニューの「NETWORK & SECURITY」から「Key Pairs」を選択します。
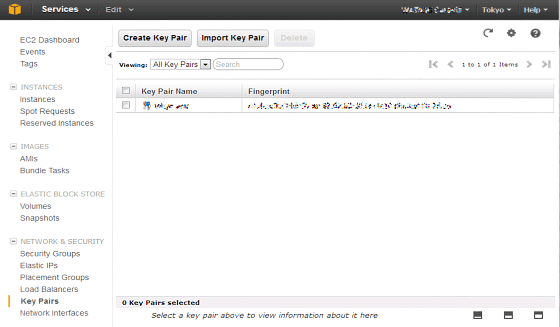
ここでは、キーペアの一覧が確認できます(初期状態ではなにもキーが表示されていません)。
キーを作成するためには、「Create Key Pair」ボタンをクリックし、ダイアログを進めます。
「Create」をクリックすることで、Key Pair Nameの入力を促されるので、任意の名前を決めると、.pemファイルが自動でダウンロードされます。
そして、credentials.jsonでは、”keypair”パラメータは、”key-pair-file”パラメータはダウンロードした.pemファイルまでのフルパスを記載します。
その後、SSH認証設定のため、配置したpemファイルに適切な権限を付与する必要があります。
$ chmod og-rwx .pem