今注目のM2Mやビッグデータへの取り組みについて、オープンソースの大規模分散処理基盤「Hadoop」や、クラウドコンピューティングを活用した、ISPの取り組みをご紹介します
by wazalabo-editor 2013/08/26
スマートフォンや各種センサーの普及で、大量データの収集が容易になり、データの高度な分析によって新しいビジネスチャンスを切り拓く企業が、近年相次いでいます。
ISPでは産業界のこうした動向を睨み、オープンソースの大規模分散処理基盤「Hadoop」やクラウドコンピューティングを活用した、ビッグデータの高速処理&分析技術を開発しています。
M2Mの最新IT技術はもちろん、今回は主にサーバ側での分散処理技術や、「Amazon EMR」のクラウドサービスを利用したビッグデータ処理のケーススタディ、Hadoopのシステム設計手法など、ISPの経験に基づいた技術ノウハウの一部を重点的にご紹介。計3回にわたって連載します。
「M2M」と「ビッグデータ」を理解する
「技ラボ」によくアクセスされている方なら、「ISPは画像処理技術が中心の会社」という印象を、もしかすると抱いておられるかも知れません。じつは「宇宙開発」や「通信」「医療」なども、ISPの重要な事業領域であり、他社にないユニークな観点で研究開発を推進しています。
たとえば、さる2013年7月には、「M2M」と「ビッグデータ技術」をテーマに、事例や開発ノウハウをご紹介するセミナーを実施しており、主に製造業の製品企画・開発部門、および研究部門の方々からご好評をいただきました。そして今回の技術情報読み物では、サーバ側の技術要素や設計ポイント、更にビッグデータ技術がどのように関わっていくかについてWeb上のセミナーのようなスタイルでご紹介していきます。
では、まずは「M2M」と「ビッグデータ」の解説からスタートです。
「M2M」とは
M2M (Machine to Machine) とは、機械同士が自律的に相互に通信するシステムのことです。ユビキタス社会の基盤であり、センサーネットワークに意味づけを与えるものと言えます。自動販売機自身が在庫状況を報告することにより、品切れを防ぐといった事例や、建設機械など高価な機械装置にGPSを搭載することで、盗難された疑いのあるものを検知し、強制的にエンジンストップさせるといった活用例が有名です。
「ビッグデータ」とは
ビッグデータとは、その名の通り、大容量のデジタルデータを指します。データそのものを指すだけではなく、大量データを解析することによって新しい傾向や知見を得ることも含めて、こう呼ばれています。
ビッグデータ活用の具体例として、ブログやSNSなどのソーシャルメディアが、たびたび話題になります。こうしたメディアでは、文字だけでなく写真や動画を含むさまざまなデータが、日々作成されています。
オンラインショップを利用するユーザの購入履歴も、典型的なビッグデータです。商品を「閲覧した」「購入した」という情報が、オンラインショップのデータベースに日々蓄積されています。
その解析結果は、数千万人・数億人という膨大なユーザの購入履歴から、同一商品を購入した人やよく似た傾向を持つ人のふるまいを分析することで、「最適」な商品をリコメンドするという、皆様にもお馴染みの手法で、ショップが活用しています。ブログの記事にはたびたび広告が表示されますが、ブログの記事内容だけでなく、読者ごとに広告の内容を厳選しているケースもあり、こうした広告宣伝にも、ビッグデータは活用されています。
このように、ビッグデータは、巨大なデータとその解析技術を組み合わせたテクノロジーだと言えます。単に処理の対象が大容量であるだけではなく、非定形なデータをリアルタイムに処理している点が、大きな特徴です。
なぜM2Mとビッグデータに注目するのか
データ解析がビジネスに有効であることは、論を待たないと思います。売れ筋商品の分析、機器・設備の故障予知など、適用範囲は広大です。ビッグデータ技術の発展に伴ってデータ量による制限が少なくなり、サンプリングだけではなく、企業が保有する全データの検索・集計・比較分析が可能になっています。
一方、M2Mの進化に伴い、従来は通信機能を持たなかった機器が自らデータを作成し、現在では機器同士で通信し合うようになっています。機器の台数が増えるに連れてデータは爆発的に増加し、しかもその対象は温度や日照量等の数値データ、現場で撮影した画像データまで拡大し、さまざまなデータフォーマットが蓄積されていくわけです。
このように、M2Mで作成&やりとりされる多種多様なデータを、巨大のデータ解析が可能なビッグデータ技術で解析することで、企業がより利便性の高いサービスを開発したり、公共空間や社会インフラの安全性が高まったりするなど、ビジネスや行政分野での幅広い可能性が期待されています。
M2Mシステムの概要
では、M2Mを念頭に、サーバ技術の解説とシステム検討時の注意点を説明していきます。
M2Mでどんなことが可能になるのか
M2Mは、センサー情報をサーバに送信し、サーバで何らかの処理を行うシステムです。たとえば、以下のような使い方が想像されます。
障害レポート
各筐体が、温度・湿度などの使用状況を取得します。これらの情報をサーバ側に送信し、ある閾値を越えた機器の記録を残してメンテナンスのお知らせに使ったり、故障前の部品交換案内に利用したりすることが考えられます。
単純な閾値(例:40度以上)ではなく、「40度以上の条件が100時間を越えた」とか「他の機器より熱い環境で使われている」など、過去の履歴や他の機器との比較を行って異常を検知するともっと優れた異常検知ができそうです。
GPS情報の追跡
M2M機器から送信されたGPS情報を元に、想定外の位置にある機器を検知し、盗難の可能性がある場合は機器を強制的にストップさせます。
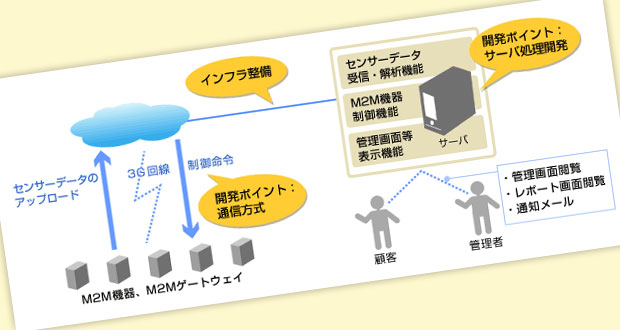
システム構成例
M2Mで実現したいことによって、さまざまなシステム構成と処理プロセスが考えられますが、多くのシステムでは、以下のようなステップでデータ処理を実現しています。
- センサーで取得したデータを、M2M機器からアップロード
- サーバ側で、センサーデータを受信・保存する。
- サーバは、受信したデータを解析して、異常値の検知などを行う。
- 何か特別なことが発見されれば、サーバから管理者に電子メールなどで通知を行う。また、管理画面やレポート画面を見ることもできる。
これを図示すると、以下のようになります。

このようなシステムを構築するには、以下が必要になります。
- インフラ整備
サーバやサーバを公開するための環境を用意します。どの程度の性能のサーバを何台用意するか・どれくらい通信帯域があれば良いか等を検討しながら構成を決めていく必要があります。 - 通信方式策定
業界標準の取り決めがある場合もある場合はともかく、一般的にはどの様なデータをどの様な順番でやりとりするか決める必要があります。M2M機器側の通信機能を開発する業者とサーバ側を開発する業者が異なる場合は、ここをしっかり決める必要があります。 - サーバ処理開発
実現したいことによって必要な機能は異なりますが、多くの場合は以下の機能を開発することになります。
・M2M機器からアップロードされたデータを受信し、処理する機能
・M2M機器を制御する機能
・管理者向けの機能
ここに挙げた物はいずれもM2M機器からのデータや管理者のアクセスをきっかけとして実施される処理ですが、集まったセンサー情報を集計したりセンサー間のデータを比較したりする様な、日単位や月単位で実行する処理も考えられます。
1台のM2M機器がわずかなデータをサーバに送る様な場合は単純なのですが、このようなシステムでは
という掛け算でシステム実現の難易度が上がっていきます。問題が起きそうな箇所を見極めながら設計するのは簡単な仕事ではないですが、非常にチャレンジングな仕事です。
サーバシステムの課題:データ量
たとえば腕時計や万歩計に通信機能を持たせ、1時間に1度、位置情報や生体情報を送信することを考えてみます。これらは、一人ひとりが所有するパーソナルな機器ですから、100万台~1000万台といった単位で市場に出回っています。ユーザ数が100万人と仮定すれば、1年経てばサーバに貯蓄されるデータ量が100万 × 24件/日 × 365日で、約9億件というデータ量になります。
たとえばその中から、ある生体情報が上位100件の人を探そうとすると、9億件のデータをソート処理することになります。同じような生体情報を持つ人を分類しようとすると、単純に考えると、100万人×100万人の類似度計算処理が必要になります。
これらの数字はあくまでも例ですが、M2Mで発生するデータ量は大容量になり得ることが、想像していただきやすいと思います。
よく使われるRDB(リレーショナルデータベース)でも、ある程度の規模なら対応できますが、ハードウェアの選択やデータベースのチューニングなど、構築・運用上の工夫が必要になってきます。データ量がさらに増加すれば、インフラの見直しが必要になりますし、ハードウェアの性能を良いものに変えていくのにも限度があります。つまり、データの保持(およびバックアップ)、データの検索や分析処理が、どんどん難しくなっていきます。
ビッグデータ技術を使うと、「分散処理」の基盤によって、これらの問題を解決することができます。さまざまな技術基盤がありますが、次回は「Hadoop」を例にビッグデータ技術をご紹介します。