
本記事は全5回のシリーズ記事「Intel Core UltraのNPUで実現するAIモデル」の第5回(最終回)です。
第1回 CPU附属のNPUを使うには
第2回 OpenVINOを使ったNPU推論
第3回 色々なCNNをNPUで実行する
第4回 OpenVINOモデルの量子化
第5回 Open VINO Gen AIを使ってLLMを実行する
はじめに
近年、大規模言語モデル(LLM)の需要は急速に高まり、エッジデバイスでも使われるようになってきました。しかし、LLMの推論は計算負荷が高く、モデルやデバイスによっては時間がかかることもあります。そこで複数のモデルやデバイスを使ってLLMを実行した際の速度比較を行いました。
本記事では、OpenVino Gen AIを使い、複数のデバイスでLLMを実行する際の方法と速度比較の結果についてご紹介させていただきます。
環境構築
今回は以下のような環境で進めていきます。
- Windows仮想環境
- デバイス
- NPU: Intel Core Ultra 内蔵 NPU(Intel® AI Boost)
- CPU: Intel® Core™ Ultra 7 155H
- iGPU: Intel® Arc™ Graphics(内蔵)
- 演算性能(ピーク TOPS (Int8) )
- 全体:33
- NPU :11
- iGPU :18
※もっと詳しい仕様を確認したい場合は以下をご参照ください。
インテル® Core™ Ultra 7 プロセッサー 155Hの仕様の詳細
pythonライブラリ
| Version | |
|---|---|
| python | 3.12.10 |
| torch | 2.5.1 |
| transformers | 4.57.3 |
モデル変換に必要な依存関係
| Version | |
|---|---|
| nncf | 2.19.0 |
| onnx | 1.20.0 |
| openvino | 2025.4 |
| openvino-genai | 2025.4 |
| openvino-telemetry | 2025.2.0 |
| openvino-tokenizers | 2025.4 |
| optimum | 2.1.0 |
| optimum-intel | 1.27.0 |
| optimum-onnx | 0.1.0 |
※versionが異なると動かなくなる可能性があります。
使用するモデル
optimum intelを使ってHugging FaceのモデルをOpenVino IRに変換するため、optimumのサポートがあるモデルを使用してください。サポートされているモデルの一覧は次のサイトから確認できます。
サポートされているモデルの一覧
今回は以下のモデルを使用しました。
※google/gemma-3-4b-itのみマルチモーダルモデル
ドライバーのインストール
以下のサイトからIntel® Core™ Ultraプロセッサ用のIntel® NPUドライバーをインストールします。
Intel® NPU Driver – Windows*
使用しているデバイスによって有効なドライバーが変わりますので、実際にお試しになる際にはご注意ください。
モデル変換に必要な依存関係のインストール
「環境構築」の項目を参考にversionに注意しながらインストールしてください。
Pythonのインストール
Python 3.12.10を以下のサイトからインストールしてください。
Python 3.12.10
windows仮想環境の作成
python -m venv npu-env
npu-env\Scripts\activate依存関係のインストール
pip install nncf==2.19.0 onnx==1.20.0 optimum-intel==1.27.0 transformers==4.57.3
pip install torchvision==0.20.1
pip install openvino==2025.4 openvino-tokenizers==2025.4 openvino-genai==2025.4また、Open VINOのインストール後、以下のようにNPUを認識しているか確認してください(Pythonのインタラクティブモード)。
>>> import openvino as ov
>>> core = ov.Core()
>>> core.available_devices
['CPU', 'GPU', 'NPU']CPU,GPU,NPUの表示があれば、大丈夫です。
Open VINO IRへの変換及び量子化
optimum intelを使ってOpen VINO IR変換と量子化を行います。
optimum intelとはHugging Faceの機械学習モデルをIntel製のCPU等で動かすための公式ライブラリです。optimum intelを使うとOpenVino IR変換とNPUで実行するための量子化を簡単に行うことができます。
また、OpenVINO IRとはOpenVINOを使うための独自のフォーマットのことです。IR変換により bin、xml の拡張子を持つファイルができ、推論に使用されます。
IR変換と量子化の方法
次のようなコマンドを実行することでIR変換と量子化を行うことができます。
optimum-cli export openvino \
-m <model name> \
--weight-format <int4 or nf4> \
--sym \
--ratio <number> \
--group-size <number> \
<directory name>-m:変換したいモデル名の指定。
–weight-format:重みの形式を指定。int4またはnf4に変換できる(nf4はIntel® Core Ultra Processors Series 2のNPUで使用可能)
–sym:対称量子化をする場合に入れる
–ratio:どのくらいの重みを量子化するかの指定。1.0なら100%量子化される。
–group-size:量子化の単位サイズ。Group quantization (GQ)の場合は整数値(128など)、Channel-wise quantization (CW) の場合は-1とする。
<directory name>:出力先ディレクトリ名。
実際の実行例を見てみます。
これはmicrosoft/Phi-3.5-mini-instructをIR変換・量子化するときのコマンドです。
optimum-cli export openvino \
-m microsoft/Phi-3.5-mini-instruct \
--weight-format int4 \
--sym \
--ratio 1.0 \
--group-size 128 \
Phi-3.5-mini-instructまた、既に量子化されたモデルを使う場合はそのままexportすることが可能です。
これはTheBloke/Llama-2-7B-Chat-GPTQをexportするときのコマンドです。
optimum-cli export openvino -m TheBloke/Llama-2-7B-Chat-GPTQ量子化されたモデルは以下のサイトから確認することができます。
int4で量子化されたモデル
4-bit (INT4) GPTQ models
NPU向けに最適化されたモデル
LLMs optimized for NPU
推論方法
当社でOSSとして公開しているベンチマークテスト「ai_inference_device_benchmark」を使用して推論を行っていきます。使用するコードはllm/openvino/benchmark_openvinoで各モデル、各デバイスの推論速度の比較をします。
評価指標は以下の通りです。
- FTL(First Token Latency)
- テキストを入力してから、最初のトークンが出るまでの時間
- TPS(Tokens per second)
- 1s当たりの平均トークン数
詳しい実行方法はドキュメントをご確認ください。
実行例としてPhi-3.5-mini-instruct(テキスト専用モデル)でtext to textを行う場合のコマンドを紹介します。(使用デバイスはNPU, CPU, iGPU)
python -m llm.openvino.benchmark_openvino \
--model-path .\LLM_benchmark\openvino_models\Phi-3.5-mini-instruct \
--inference-mode text \
--model-type llm \
--device NPU CPU GPU–inference-modeのtextをimageに変更するとimage&text to textの推論ができます。
また、マルチモーダルモデル(今回はgemma-3-4b-it)を使う場合は–model-typeのllmをvlmに変更してください。
推論結果
今回の推論では各モデルをint4で対称量子化したものを使用しています。
入力したプロンプトと出力トークン数は次の通りです。
- 入力プロンプト
- text to text:「Explain quantum computing in about 100 tokens.」
- image&text to text:「What is this picture?」+犬の画像
- 出力トークン数
- 100程度
以下の二つのグラフはtext to textで推論を行った際の結果です。
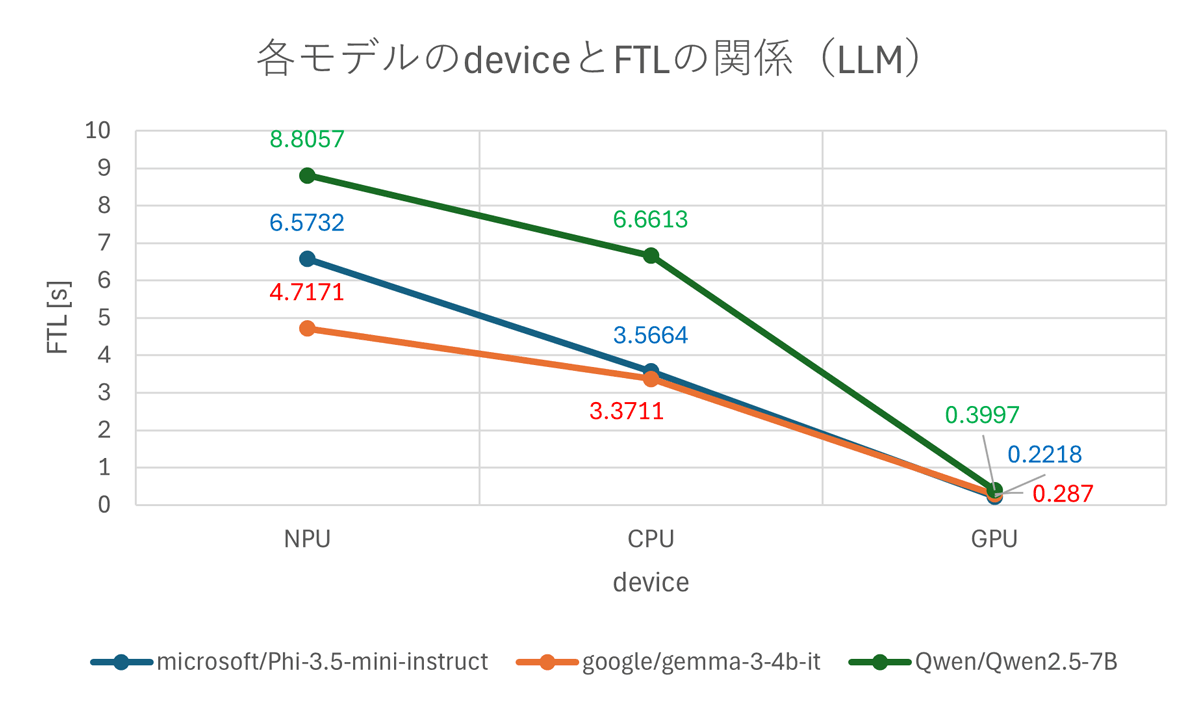
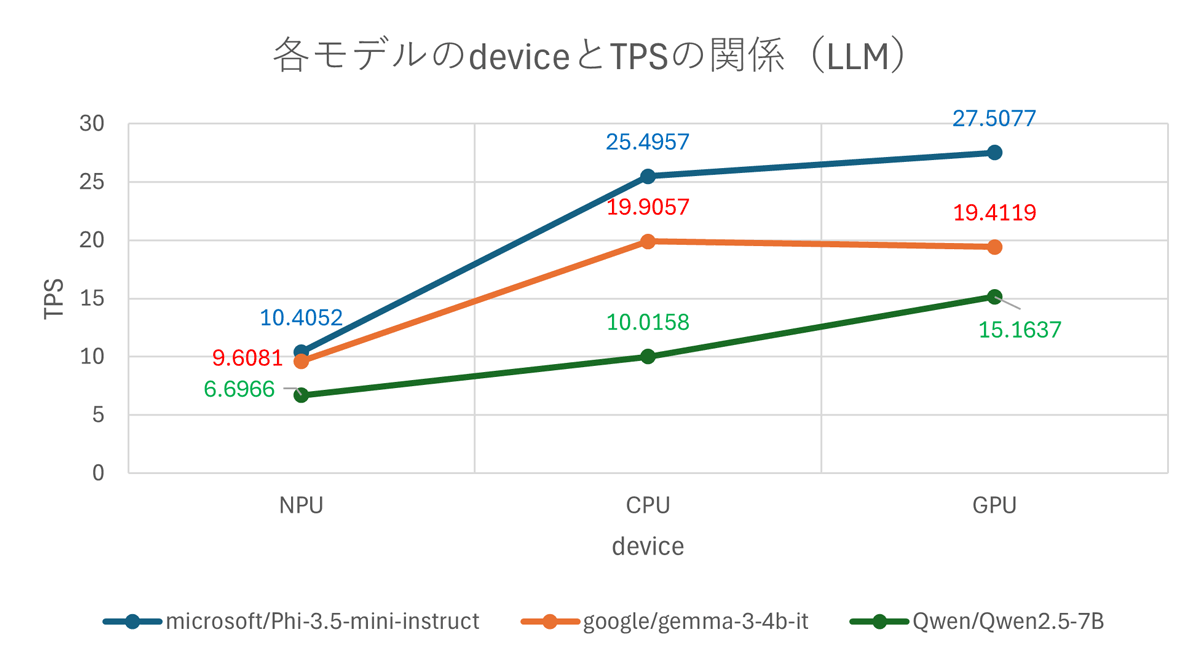
FTL は小さい方が良く、TPS は高い方が良い指標です。今回の実験結果から NPU < CPU < iGPU の順に高速なことが分かります。その理由は各デバイスの得意不得意とLLM推論をする際の処理が関係しています。詳しくは「NPUはLLM推論に向かないのか?」を参照してください。
また、Qwen2.5-7Bは推論速度が遅く、他のモデルはあまり変わらない結果となりました。
これはQwen2.5-7Bのモデルサイズが約7.6Bであるのに対し、他のモデルは約4Bと小さいためと考えられます。
次の二つのグラフはimage&text to textで推論を行った際の結果です。参考のため、先ほどのtext to textの結果も合わせて表示しています。
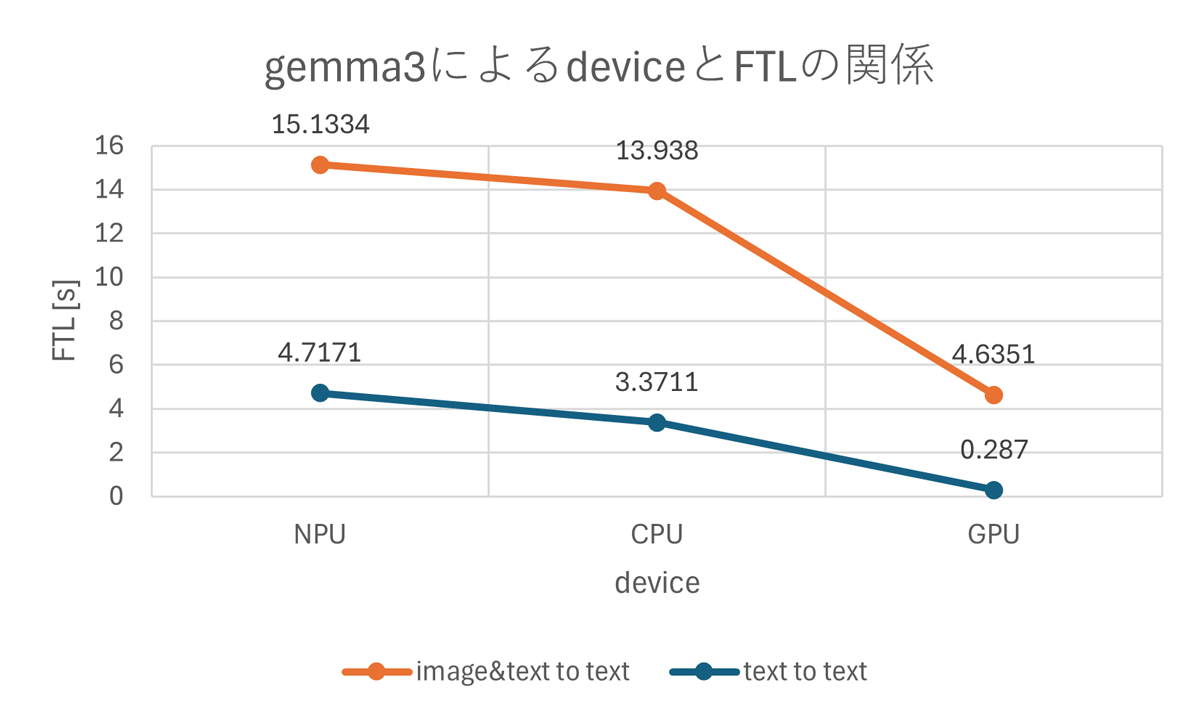
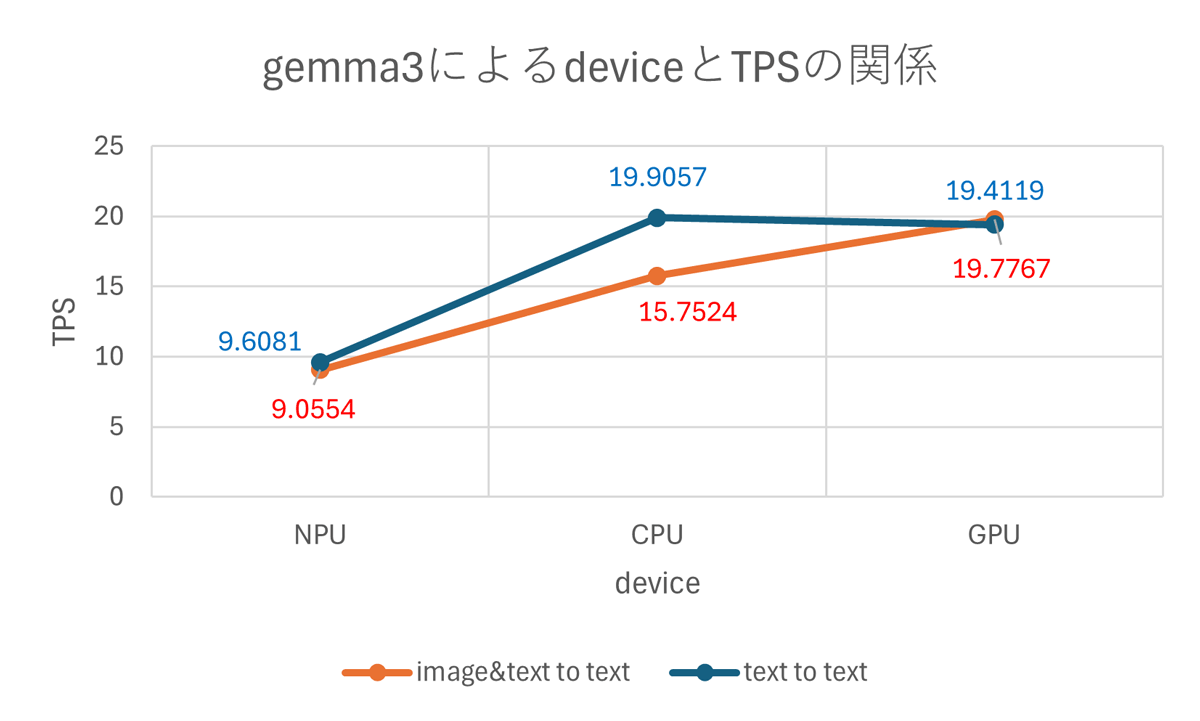
これらのグラフからimage&text to textの場合はtext to textの時よりFTLが大きくなることが分かります。画像処理の分だけ時間がかかっているのが原因と考えられます。一方でTPSでは大きな差が出ませんでした。これはどちらもテキストを出力し、画像の有無はTPSに影響しないためと思われます。
NPUはLLM推論に向かないのか?
NPUとはAIや機械学習の処理に特化したプロセッサのことです。ニューラルネットワークの演算を効率的に実行することができるため、LLM推論にも向いていそうに見えます。
しかし、実際にLLM推論を実行し、CPUやiGPUと比較すると推論速度が遅いという結果となりました。では、なぜこのような結果となったのでしょうか。
以下の内容はあくまでCore Ultra のアーキテクチャを前提とした説明です。
次の表は各デバイスの主な用途や得意不得意をまとめたものです。
| NPU | CPU | GPU | |
|---|---|---|---|
| 主な用途 | AI・機械学習用 | 汎用 | 画像処理を起点に発展した並列計算用 |
| 得意分野 | 定型的な大規模行列演算(GEMM、Conv)、高スループット | 逐次処理、条件分岐、制御処理、低レイテンシ | 大規模行列演算、並列処理、メモリ帯域を活かした処理 |
| LLM推論の中で得意な処理 | Attentionスコア(QKT)の計算・FFN | QKV生成(NPU, GPUより比較的得意)、softmax・活性化関数などの小規模・分岐を含む処理 | QKV生成、Attention(QKT・softmax含む)、FFN、重み・KVキャッシュのロード |
| LLM推論の中で苦手な処理 | 不規則なメモリアクセス、KVキャッシュの頻繁なロード、動的形状処理 | Attentionスコア(QKT)の計算、FFNなどの大規模GEMM、高帯域処理 | 小バッチ・短シーケンスでの実行(並列度不足による効率低下) |
| トークン数 | 多いとKVキャッシュのロードに時間がかかり、少ないとQKVの生成やSoftmax関数の計算で効率が落ちる | 少ない方が良い(低レイテンシ重視) | 多い方が良い(長文・バッチ化で効率向上) |
この表を見ると、一概にLLM推論の処理といってもその中に得意な処理、苦手な処理が含まれていることが分かります。
NPUはAI・機械学習での大規模行列計算が得意で一般的にはFFNなどの処理に向いています(Core UltraのNPUはCNN最適化寄りのため、FFNの高速化は限定的)。一方でKVキャッシュはほとんどDRAMに保存されるため、ロードに時間がかかります。また柔軟性が低く、 ロード待ちを隠蔽しにくいため、ロード完了まで処理が停滞しやすいです。
GPUはNPUと同じく、大規模行列計算が得意であり、KVキャッシュのロードにも時間がかかります。しかし、動的スケジューリングが可能なため、ロード中に他の処理ができる場合があります。
反対にCPUは大規模行列計算が苦手ですが、小規模・分岐を含む計算は得意です。今回は入力トークンが少ないため、比較的CPUで処理しやすかったのではないかと思われます。
今回は推論速度がNPU < CPU < iGPUとなりましたが、モデルや入力トークン数、NPU・CPU・GPUの種類などによって結果が変わることがあります。特にスケジューリングやメモリアクセス時間の問題はNPU製品ごとのアーキテクチャによります。一概にNPUはLLM推論に向かないと決めず、状況や用途によってふさわしいデバイス・モデルの使用をしてください。
ai_inference_device_benchmark
この記事で使用しているベンチマークテストは当社でOSSとして公開しています。様々なデバイスやフレームワークでCNNやLLMモデルの比較が可能です。
ai_inference_device_benchmark
終わりに
最初は漠然とNPUはLLM推論が得意なのではと思っていましたが、実際にはいくつかのボトルネックが存在していたことが分かりました。今回の結果を見るとNPUは使いにくいのではと感じるかもしれませんが、多くのメリットもあります。例えば、NPUは消費電力が少なく、エッジAIへの利用に向いています。また、NPUを使うことでCPUやGPUの負担を減らし、AI以外の処理をスムーズにすることも可能です。このことから状況や用途に合わせてNPUを効果的に活用していくことが大切なのではないかと思われます。