by Watase Satoshi 2016/6/2
はじめに
Amazon Web Service(以降AWS)のIaaSであるEC2のGPUインスタンスを用いてDeep learningフレームワークCaffeを動かしてみます。ただ動かすだけでは味気ないので今までオンプレミスサーバやJetsonで動作させてきた実績のあるハンドサイン認識器の移植を試みましょう。ハンドサイン画像認識に関しての詳細は以下の技ラボ記事を参照してください。
Deep Learningによるハンドサイン画像認識デモ 解説 (第一回)
Deep Learningによるハンドサイン画像認識デモ 解説 (第二回)
Deep Learningによるハンドサイン画像認識デモ 解説 (第三回)
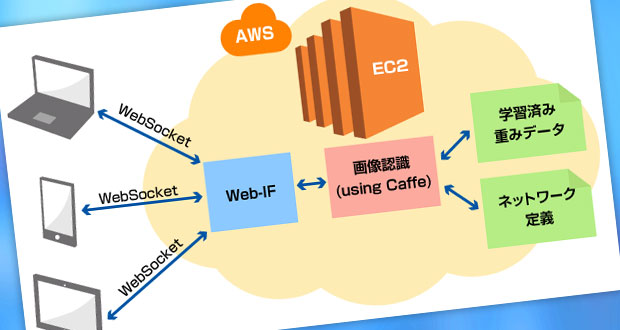
今回動作させた仕組みの概略は以下の通りです。
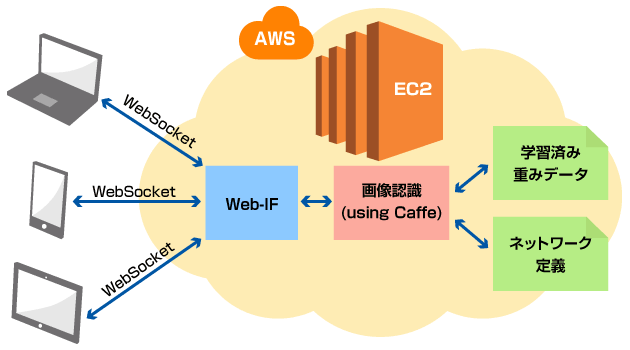
「クラウドでハンドサイン認識サーバを立ててみた」は「環境構築編」と「アプリ評価編」の全2回でお送りします。今回は環境構築の話。
環境構築では、AWSのスポットインスタンスを立ち上げ、Cuda7.5+cuDNNv4+Caffe+Python2.7を動作させる環境を構築します。 起動直後のEC2インスタンスのサーバ内環境は不変ですので、この環境構築はインスタンス起動ごとに毎回同じ手順を行う必要があります。 何度も手作業でやることでもないので、このプロビジョニング操作はコマンド1発で済むよう自動化したいところです。
技術要素
- Deep Learning
- AWS
- スポットインスタンスb
- Itamae
- リモートサーバーのプロビジョニング
GPUインスタンスの起動
「どんなインスタンスを起動すればいいの?」
まずはGPUインスタンスに関して情報を整理しましょう。AWSでは2016/5/24時点で以下の2種類のGPUインスタンスがあります。
| インスタンス名 | vCPU | ECU | メモリ (GiB) |
インスタンス ストレージ |
GPU spec | 料金 |
|---|---|---|---|---|---|---|
| g2.2xlarge | 8 | 0.73 | 15 | 60 SSD | GRID K520 x 1 | $0.65/hour |
| g2.8xlarge | 32 | 104 | 60 | 2×120 SSD | GRID K520 x 4 | $2.6/hour |
上の表を見れば一目瞭然ですが、g2.2xlargeの4倍のスペックがg2.8xlargeです。これは単純にg2.8xlargeのマシンを4インスタンスで共有してg2.2xlargeとして利用しているから。GPU4枚差しのマシンということですね。したがって、g2.8xlargeを効率的に利用するためにはマルチGPUでもスケールできる処理を流すべきです。そうでない場合はg2.2xlargeを利用するのが無難ではないかと思います。
今回動作させようとしているハンドサイン判別ソフトウェアはシングルGPUでの動作を想定したものですので、g2.2xlargeが良さそうです。
スポットインスタンスの起動
AWS管理をWeb画面から行うAWS Consoleでg2.2xlargeを起動してみます。今回のハンドサイン認識器はあくまでも評価として一時的に動作させるものですので、比較的安価なスポットインスタンスを利用してみます。
スポットインスタンスとは、ざっくり言うとインスタンスのオークションのようなものです。AWSではいかなる時にもユーザからのインスタンス要求に応えられるように、常に余剰リソースを保持しています。その余剰リソースの一部を、そのときの需要と供給に応じた時価で提供する仕組みがスポットインスタンスです。利用者は「この値段なら利用したい」という価格を入札し、時価がその価格を下回らない時間だけインスタンスを利用することができます。時価は場合によっては通常のオンデマンドインスタンスの1/10程度の安価となる時もあれば、逆にオンデマンドインスタンスを遥かに上回る価格まで高騰することもあります。
現状(2016/5/25時点)のGPUインスタンスのスポットインスタンス相場を眺める限り、Tokyoリージョン(ap-northeast-1)のGPUインスタンスは需要過多となる場合が多いらしく、日に何度かオンデマンドインスタンスの10倍程度まで高騰してしまっています。入札額を時価が上回った場合は強制的にインスタンスが終了してしまいますので、これは少し手を出しづらい値動きです。一方、Tokyoリージョンより規模が大きいVirginiaリージョン(us-east-1)は値動きがそれほど大きな振れ幅でなく、おおよそオンデマンドインスタンス以下の価格で推移しています。これは使えそうです。
AWS Consoleを開き、右上のリージョン選択で「N.Virginia」を選択した上で、Spot Requestの画面を開きます。この画面では現在の入札ステータスを確認することができます。
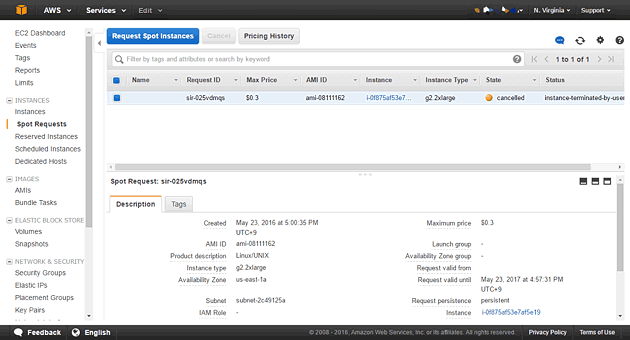
Spot Request画面上部の「Pricing History」をクリックすることで、すべてのインスタンスのスポットインスタンス価格をグラフィカルな画面で確認することができます。g2.2xlargeのオンデマンドインスタンス価格は$0.65ですので、この日のg2.2xlargeインスタンスはおおよそオンデマンドインスタンス以下の価格で推移しているようです。
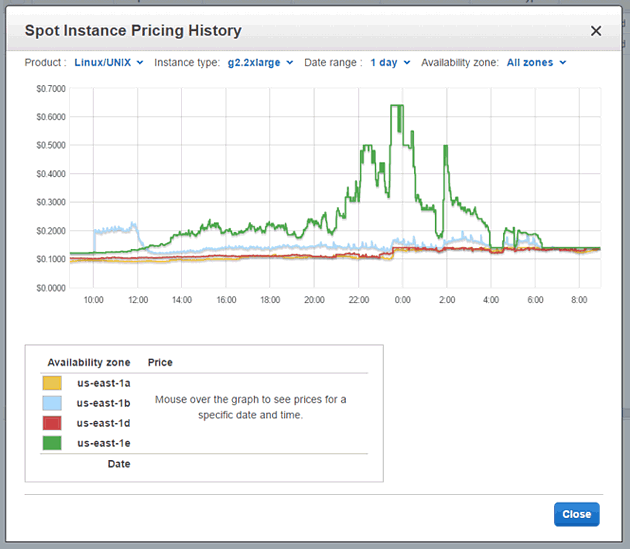
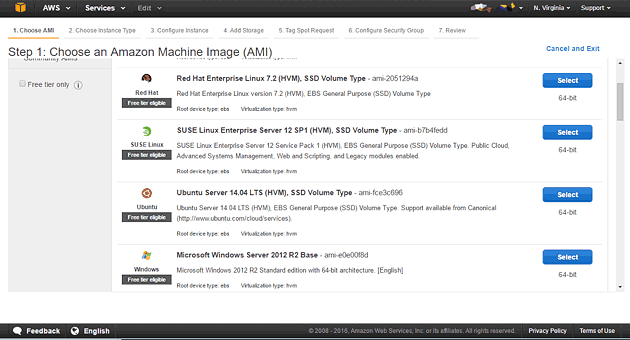
Spot Request画面に戻り、「Request Spot Instances」ボタンをクリックします。すると、インスタンスで動作させるマシンイメージ(AMI)の選択画面が表示されます。ここではUbuntu Server 14.04 LTSを選択しました。
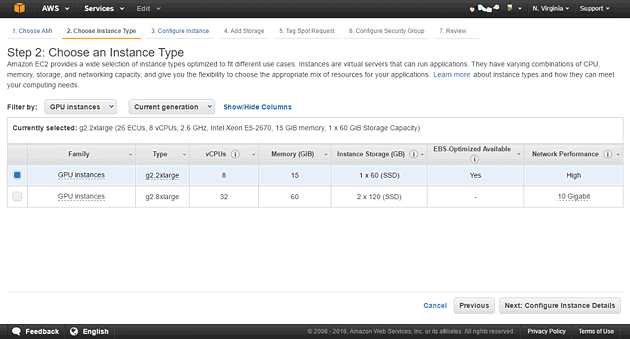
次にインスタンスタイプの選択画面に遷移します。g2.2xlargeを選択します。
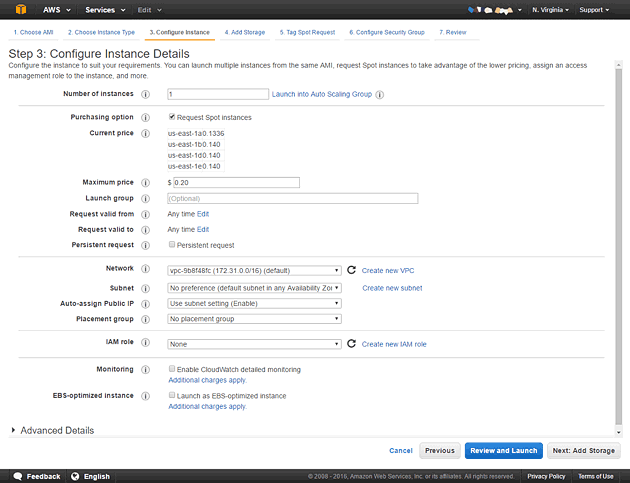
スポットインスタンス価格の入札額を指定します。「Maximum price」項目が入力項目です。直上の「Current Price」にて現在の価格が表示されていますね。 ここでは少しそれを上回る$0.2を指定してみました。これで動作できればオンデマンドインスタンスの1/3以下の価格で使えることになります。このまま起動させることもできますが、 インストール作業の兼ね合いで追加のストレージを指定する必要があります。下の「Next:Add Storage」ボタンをクリックします。
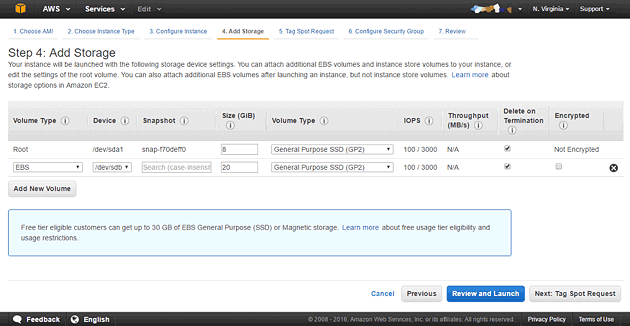
g2.2xlargeインスタンスはデフォルトのRootVolumeでは8GBしかストレージ容量がありませんので、20GB程度のEBSを追加しておきます。 この際、インスタンス終了時にストレージが自動で削除されるように「Delete on Termination」にチェックを付けると良いでしょう。 「Review and Launch」ボタンをクリックして先に進みましょう。
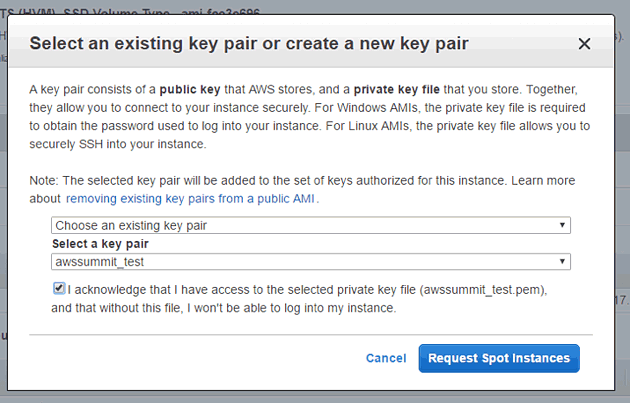
スポットインスタンスリクエストのレビュー画面です。セキュアな環境でインスタンスを起動したい場合はAmazon VPC環境で起動すべきですが、 今回は検証目的なのでSecurity Group設定で、自分のIPのみ22番ポートを開け、サーバアプリを動作させる8080ポートは全開放にしておきます。 いよいよ設定が終わったので「Lauch」ボタンをクリックします。
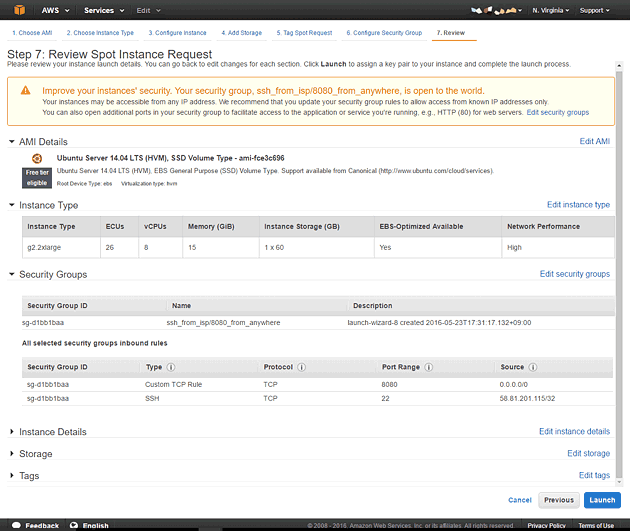
確定前にキーペアの選択画面になりますので、SSHログインに利用する秘密鍵を指定しておきます。
ここまでの操作で、スポットインスタンスのリクエストは完了です。スポットインスタンスの価格が高騰していないかぎり、 スポットインスタンスリクエストは受理され、数分で要求したEC2のインスタンスが起動します。
環境構築
EC2のインスタンスは起動しましたが、このままでは素のUbuntu Serverです。 GPUドライバも入っていないため、GPUも使えません。 また、ハンドサイン認識器はDeep LearningフレームワークCaffeで学習させたネットワークを利用しますので GPGPU環境CudaやDeep Learning用ライブラリcuDNNも使えるようにしなければなりません。 また、アプリはPythonで実装しますのでPython環境やopenCV,numpyなどの必要なライブラリも準備が必要です。
これらをすべて手作業で導入するだけでも1時間はかかります。とてもやってられません。 そのため、なんらかの手段で自動プロビジョニングを行うべきでしょう。 Puppet、Chef、Ansibleなどミドルウェアインストールなどを自動化する構成管理ツールは多数ありますが、今回は最近ruby製プロビジョニングツールItamaeを利用しました。 実はこのツールは初めて使ったのですが、事前準備はローカルにItamaeを動作できる環境を作るだけで済み、 シンプルなRuby DSL記述で処理を作りこみできる点が非常に便利でした。
例えば、GPUドライバとCuda7.5のインストールは以下のような記述をするだけで済みます。
execute 'apt-get install -y linux-image-extra-`uname -r`'
execute 'apt-get install software-properties-common'
execute 'add-apt-repository -y ppa:graphics-drivers/ppa'
execute 'apt-get update'
execute 'apt-get install -y nvidia-352'
### cuda7.5
cuda_url = 'http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/cuda-repo-ubuntu1404_7.5-18_amd64.deb'
cuda_deb_file = File.basename(cuda_url)
cuda_sha256sum = 'D8B208458B399832C312609A00074BA5858182D128C825FC55A6A35D0A5A4C62'
execute 'Get cuda-repository' do
command "curl -OL #{cuda_url}"
cwd '/tmp'
not_if "sha256sum #{cuda_deb_file} 2>/dev/null | grep -q #{cuda_sha256sum}"
end
execute 'install cuda-repository' do
command "dpkg -i #{cuda_deb_file}"
cwd '/tmp'
end
execute 'apt-get update'
package 'cuda'
このように記述したItamaeレシピはローカル環境で以下のコマンドを叩くだけでリモートのEC2インスタンスに流すことができます。 g2.2xlargeの場合、すべての環境設定が走り終えるまで30分程度かかりました。
$ itamae ssh -h {{EC2インスタンスのグローバルIPアドrス}} -u ubuntu {{Itamaeレシピファイル}} -i {{AWS KeyPairファイル}}
まとめ
AWS上でハンドサイン認識サーバを動作させるまでの環境構築の大まかな手順をご紹介しました。ここまでの作業では、主に手を動かしたのはAWSコンソールでスポットインスタンスの設定をしていた5分程度です。それだけの手間で環境の整ったGPUマシンが1時間数十円で利用できるようになるというところにクラウド環境のパワーを感じます。次回は「アプリ評価編」と題し、この環境上でハンドサイン認識サーバを動かして、その評価を行います。