問題のモデル化
検出ロジックを考えるにあたり、まずは問題をモデル化します。以下、条件付き確率の基本的な知識があることを想定しています。
画像の情報はRGBの値(画素値)がただ並んでいるだけの配列であり、人がいるかどうかを判断するためには何らかのモデル化(定式化)が必要です。
ある時刻


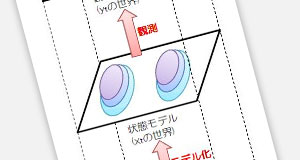
まずは今回のモデル化のイメージを図示してみます。

この図のようにモデル化とは現実世界を簡略化・抽象化し、
まず状態モデルの空間を、現実世界から、ある確率分布")
")
と表します。※2(ここで記号

")
また、今回の問題設定では白い背景の前を人が動くことになっているので、人の位置が変わればそれに応じて画素値の配列も変わることが予想されます。つまり観測データ
")
と表されます。※3
現実世界からではなく、
ここで改めて今回の目的を思い出してみましょう。目的は「単色背景上を動く人物の重心座標を求めること」でした。我々が直接得ることができる情報は、ある時刻
すなわち、「観測ベクトル")
 = \frac{ p(y_t|x_t)p(x_t) }{ \sum p(y_t|x_t)p(x_t) }")
と変形できます。すなわち(3)式の右辺を計算することが当面の目標となります。
次回はこの式を計算する方法について述べていきます。
※1 厳密にはそれぞれ確率空間であり、必ずしも2次元平面で図示できるわけではありませんが、ここではイメージを優先しました。
※2 通常、
")
※3 (1),(2)式をまとめて状態空間モデルと呼びます。
※4 より正確には